Week 3 — Reasoning, Judgment & Decision-Making第3週 — 推論・判断・意思決定
Day 1: May 12 (Tue) · Day 2: May 14 (Thu), 2026第1日: 5月12日(火)・第2日: 5月14日(木), 2026年
Day 1 — The Normative Ideal第1日 — 規範的理想
Day 1 Agenda第1日 アジェンダ
- Tutorial Part 1 — Beliefs → Actionsチュートリアル Part 1 — 信念から行動へ 0:00
- Tutorial Part 3 — Reading Code with AIチュートリアル Part 3 — AIとコードを読む 0:15
- Break休憩 0:35
- From Beliefs to Decisions信念から意思決定へ 0:40
- Bayesian Reasoningベイズ的推論 0:45
- Decision Theory意思決定理論 1:05
- The Normative-Descriptive Gap規範と記述のギャップ 1:30
- Break休憩 1:35
- Tutorial Part 2 — EMA vs Bayesianチュートリアル Part 2 — EMA対ベイズ 1:45
- Tutorial Part 4 — MP2 Demoチュートリアル Part 4 — MP2デモ 2:00
- MP2 Launch + Close課題開始 + クロージング 2:10
Today’s downloads本日のダウンロード
From the course page → Phase 2 cards → click and enter the password:
| Item | Password |
|---|---|
| T2 — bridge tutorial | jellyfish-29 |
| MP2 (Assignment) — buggy ε-greedy agent | anglerfish-56 |
Grab both now so you’re ready when each segment starts.
Course page: aps-i.chibatech.dev/course/
コースページ → Phase 2 のカード → クリックしてパスワードを入力:
| 項目 | パスワード |
|---|---|
| T2 — ブリッジ・チュートリアル | jellyfish-29 |
| MP2(課題) — バグ入りε-greedyエージェント | anglerfish-56 |
各セグメントが始まる前に両方ダウンロードしておくこと。
コースページ:aps-i.chibatech.dev/course/
Tutorial Part 1 — Beliefs → Actionsチュートリアル Part 1 — 信念から行動へ
How did you decide in MP1?MP1ではどう決めましたか?
You ended MP1 with a recommendation: “Fish in Zone X.”
How did you actually make that decision? What did you do with your beliefs?
Common moves (capture on board):
• Pick the zone with the highest expected density
• Weight by confidence — “I’m more sure about Southern Reef”
• Rule out anything below a survival threshold
We’ll formalize this after the break.
MP1の最後に、皆さんは「ゾーンXで釣る」という判断を出しました。
実際にはどうやってその判断を下しましたか?信念をどう使いましたか?
よくある選び方(黒板に書き留めて):
• 期待値が一番高いゾーンを選ぶ
• 自信の高さで重みづけ — 「Southern Reefは確信がある」
• 生存に必要な最低ライン未満は除外する
休憩後に [JA-TODO: “formalize” technical term] 形式化します。
Quick scenario — what would YOU do?考えてみよう — あなたならどうする?
Your agent has fished 20 times. Current beliefs:
• Southern Reef: ~60 fish (10 visits, confident)
• Eastern Shallows: ~55 fish (8 visits)
• Deep Water: caught 30 fish (only 2 visits — could really be anywhere)
Should the agent ever try Deep Water again? Why or why not?
(Discussion. Capture proposals. We’ll see one formal answer in the lecture block.)
エージェントは20回釣りをした。現在の信念:
• Southern Reef:約60匹(10回訪問、自信あり)
• Eastern Shallows:約55匹(8回訪問)
• Deep Water:30匹獲れた(2回しか訪問していない — 本当はどこにあってもおかしくない)
エージェントはDeep Waterをもう一度試すべきか?なぜ?
(議論。提案を記録。授業では一つの形式的な答えを見ます。)
Up next — Day 1 agenda次はここ — 第1日 アジェンダ
- Tutorial Part 1 — Beliefs → Actionsチュートリアル Part 1 — 信念から行動へ 0:00
- Tutorial Part 3 — Reading Code with AIチュートリアル Part 3 — AIとコードを読む 0:15
- Break休憩 0:35
- From Beliefs to Decisions信念から意思決定へ 0:40
- Bayesian Reasoningベイズ的推論 0:45
- Decision Theory意思決定理論 1:05
- The Normative-Descriptive Gap規範と記述のギャップ 1:30
- Break休憩 1:35
- Tutorial Part 2 — EMA vs Bayesianチュートリアル Part 2 — EMA対ベイズ 1:45
- Tutorial Part 4 — MP2 Demoチュートリアル Part 4 — MP2デモ 2:00
- MP2 Launch + Close課題開始 + クロージング 2:10
Tutorial Part 3 — Reading Code with AIチュートリアル Part 3 — AIとコードを読む
The buggy snippetバグのあるコード片
Work with AI. There are 3 bugs. We’ll do this in two stages.
function pickBestZone(beliefs) {
let bestZone = null;
let bestValue = Number.MIN_VALUE;
for (let i = 0; i <= beliefs.length; i++) {
if (beliefs[i].value > bestValue) {
bestValue = beliefs[i].value;
bestZone = beliefs[i];
}
}
return bestZone;
}
function updateBelief(oldBelief, newObs, learningRate) {
return oldBelief + learningRate * newObs;
}You don’t need to know JavaScript. You need to know what this code SHOULD do — from MP1.
AIと作業。バグは3つある。2段階で進める。
function pickBestZone(beliefs) {
let bestZone = null;
let bestValue = Number.MIN_VALUE;
for (let i = 0; i <= beliefs.length; i++) {
if (beliefs[i].value > bestValue) {
bestValue = beliefs[i].value;
bestZone = beliefs[i];
}
}
return bestZone;
}
function updateBelief(oldBelief, newObs, learningRate) {
return oldBelief + learningRate * newObs;
}JavaScriptの知識は不要。コードが本来何をすべきか — MP1で学んだこと — を理解していればよい。
Stage 1 — Trace with AIステージ1 — AIと一緒にたどる
5 minutes. Tutorial → Part 3 → Stage 1.
Trace two candidate updateBelief formulas with AI as a calculator — step by step.
Don’t ask AI which formula is correct yet — that’s your job to figure out from the numbers.
5分。チュートリアル → Part 3 → ステージ1。
updateBeliefの2つの候補式をAIを計算機として使ってたどる — 1ステップずつ。
どちらが正しいかはまだAIに聞かない — それはあなたが数値から判断する。
Stage 2 — Find all 3 bugsステージ2 — 3つのバグを全部見つける
5 more minutes. Tutorial → Part 3 → Stage 2.
Stage 1 told you which updateBelief formula is broken. Now find the other 2 bugs — with AI’s help.
Bugs 1 and 2 are JavaScript-level — AI catches them easily.
さらに5分。チュートリアル → Part 3 → ステージ2。
ステージ1でupdateBelief式のどちらが壊れているかは分かった。次は、スニペット内の他の2つのバグを見つける — AIと一緒に。
バグ1と2はJavaScriptレベル — AIが簡単に見つける。
Bug revealバグの解答
Bug 1 — Number.MIN_VALUE (JS gotcha — AI catches easily)
MIN_VALUE is the smallest positive number, not −∞. Should be -Infinity.
Bug 2 — i <= beliefs.length (off-by-one — AI catches easily)
Arrays are 0-indexed. Should be i < beliefs.length.
Bug 3 — wrong EMA formula (the conceptual one)
Current: oldBelief + α · newObs
Correct: oldBelief + α · (newObs − oldBelief)
The current formula doesn’t subtract the old belief — beliefs grow without bound.
You catch this with MP1 intuition: beliefs should converge toward truth, not blow up.
バグ1 — Number.MIN_VALUE (JSの落とし穴 — AIが簡単に見つける)
MIN_VALUEは最小の正の数で、−∞ではない。-Infinityが正しい。
バグ2 — i <= beliefs.length (off-by-one — AIが簡単に見つける)
配列は0始まり。i < beliefs.lengthが正しい。
バグ3 — EMA式が誤り (概念的なバグ)
現状: oldBelief + α · newObs
正しい: oldBelief + α · (newObs − oldBelief)
現状の式は古い信念を引いていない — 信念が際限なく増えてしまう。
MP1の直感で気づける:信念は真実にJA-TODO: “converge”収束すべきで、爆発してはいけない。
Break — 5 minutes休憩 — 5分

Up next — Day 1 agenda次はここ — 第1日 アジェンダ
- Tutorial Part 1 — Beliefs → Actionsチュートリアル Part 1 — 信念から行動へ 0:00
- Tutorial Part 3 — Reading Code with AIチュートリアル Part 3 — AIとコードを読む 0:15
- Break休憩 0:35
- From Beliefs to Decisions信念から意思決定へ 0:40
- Bayesian Reasoningベイズ的推論 0:45
- Decision Theory意思決定理論 1:05
- The Normative-Descriptive Gap規範と記述のギャップ 1:30
- Break休憩 1:35
- Tutorial Part 2 — EMA vs Bayesianチュートリアル Part 2 — EMA対ベイズ 1:45
- Tutorial Part 4 — MP2 Demoチュートリアル Part 4 — MP2デモ 2:00
- MP2 Launch + Close課題開始 + クロージング 2:10
From Beliefs to Decisions信念から意思決定へ
Bridge into the lecture授業ブロックへの橋渡し
You just spent 35 minutes connecting MP1 to a buggy agent.
Two weeks ago: you formed beliefs about fish populations.
You ended MP1 with: “Fish in Zone X.”
This week: we formalize what you DO with beliefs.
• Day 1 — How agents SHOULD reason and decide (normative)
• Day 2 — How humans ACTUALLY reason and decide (descriptive)
The gap between the two is the intellectual heart of the week.
皆さんは35分かけて、MP1とバグだらけのエージェントを繋げてきた。
2週間前:魚の数についての信念を形成した。
MP1の最後は「ゾーンXで釣る」という結論だった。
今週:信念をどう使うかを形式化する。
• 第1日 — エージェントはどう推論・決定すべきか(規範的)
• 第2日 — 人間は実際にどう推論・決定するか(記述的)
両者のギャップが今週の知的な核心。
Up next — Day 1 agenda次はここ — 第1日 アジェンダ
- Tutorial Part 1 — Beliefs → Actionsチュートリアル Part 1 — 信念から行動へ 0:00
- Tutorial Part 3 — Reading Code with AIチュートリアル Part 3 — AIとコードを読む 0:15
- Break休憩 0:35
- From Beliefs to Decisions信念から意思決定へ 0:40
- Bayesian Reasoningベイズ的推論 0:45
- Decision Theory意思決定理論 1:05
- The Normative-Descriptive Gap規範と記述のギャップ 1:30
- Break休憩 1:35
- Tutorial Part 2 — EMA vs Bayesianチュートリアル Part 2 — EMA対ベイズ 1:45
- Tutorial Part 4 — MP2 Demoチュートリアル Part 4 — MP2デモ 2:00
- MP2 Launch + Close課題開始 + クロージング 2:10
Bayesian Reasoning — The Normative Idealベイズ的推論 — 規範的理想
Bayes’ rule — quick reviewベイズの定理 — 復習
In Week 2 you re-derived multiply-and-normalize with Chibany.
P(H \mid D) = \frac{P(D \mid H)\;P(H)}{P(D)} \;\propto\; P(D \mid H)\;P(H)
• P(H) — prior
• P(D \mid H) — likelihood
• P(H \mid D) — posterior
You used this all of MP1. Today we make it rigorous: why Bayes?
(Color convention: orange = prior, blue = likelihood, yellow = posterior. We’ll reuse these later.)
第2週でチバニーを使って掛けて正規化を再導出した。
P(H \mid D) = \frac{P(D \mid H)\;P(H)}{P(D)} \;\propto\; P(D \mid H)\;P(H)
• P(H) — 事前確率
• P(D \mid H) — 尤度
• P(H \mid D) — 事後確率
MP1全体で使ってきた。今日は厳密に:なぜベイズか?
(色の決まり:オレンジ=事前、青=尤度、黄色=事後。後でもう一度使う。)
Why Bayes? The Dutch bookなぜベイズか — ダッチブック論証
Setup. A forecaster says: P(rain) = 0.6 and P(no rain) = 0.6. The two add to 1.2 — not coherent.
The con. I sell them both tickets at fair-by-their-numbers prices:
- They pay me: $0.60 + $0.60 = $1.20
- Tomorrow, exactly one ticket pays out: $1.00
- I keep $0.20. Guaranteed. No matter what the weather does.
That’s a Dutch book — a set of bets you’re guaranteed to lose.
The generalization. The same logic extends to updating: any belief revision that isn’t Bayes’ rule can be Dutch-booked across two days.
Bayes isn’t one option among many. It’s the unique coherent answer.
設定。ある天気予報士:P(雨) = 0.6、P(雨でない) = 0.6。合計1.2 — 整合的でない。
仕掛け。両方のチケットを彼の言い値で売る:
- 受け取り:$0.60 + $0.60 = $1.20
- 翌日、ちょうど1枚だけ当たる:$1.00
- 純利益$0.20。確実に。天気がどうであれ。
これがダッチブック — 確実に負ける賭けの組み合わせ。
一般化。同じ論理は更新にも当てはまる:ベイズの定理以外の更新規則は、2日間でダッチブックの餌食になる。
ベイズは数ある選択肢の一つではない。唯一の整合的な答え。
Generative model — think forward生成モデル — 前向きに考える
To use Bayes, ask: “How would the data have been generated if H were true?” Story: a deep-ocean zone is either rich (~80 fish) or empty (~10 fish); observations are noisy.
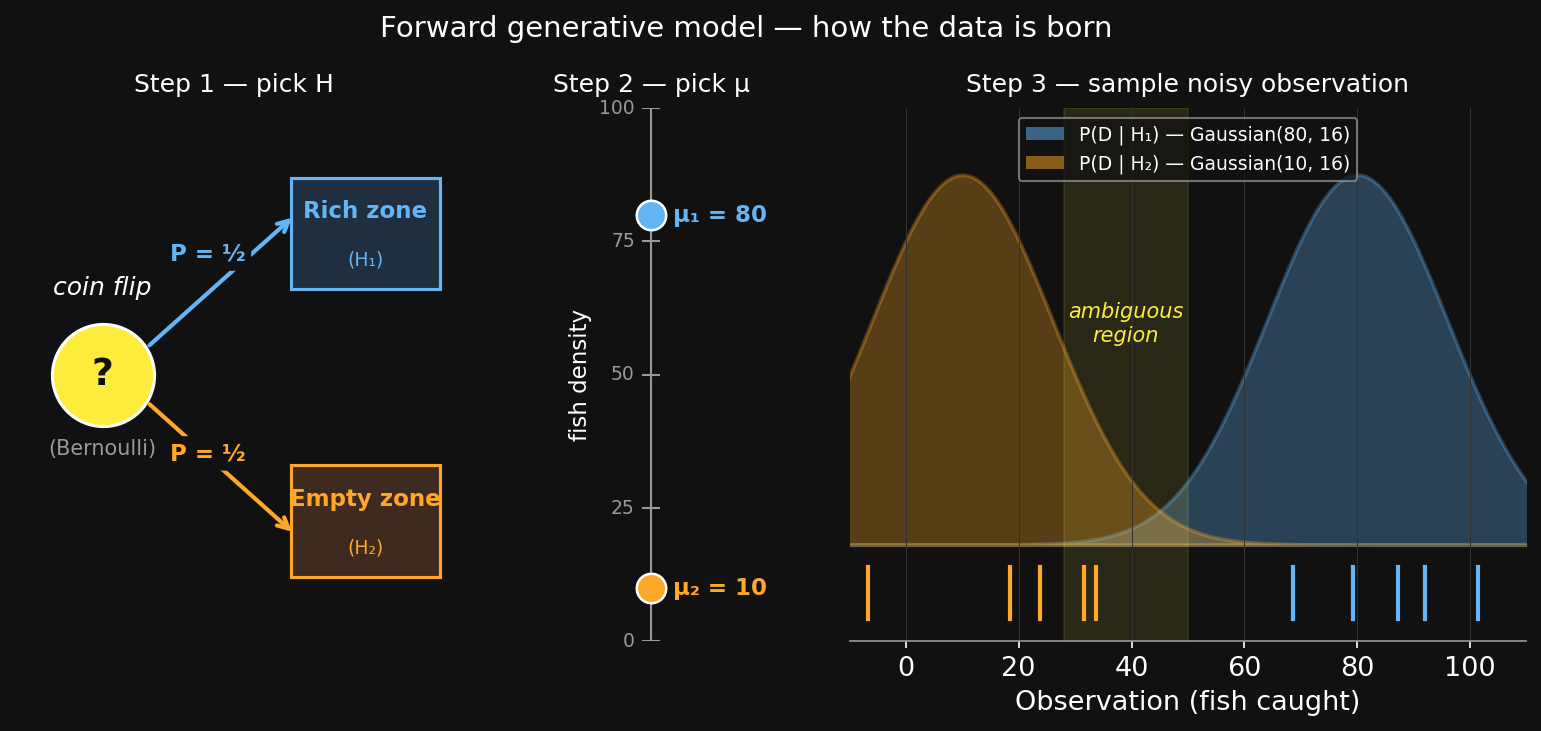
Three steps: flip a coin to pick H (Bernoulli) → that fixes a true mean μ → sample a noisy observation (Gaussian around μ).
ベイズを使うには、こう問う:「仮説Hが真なら、データはどう生成されるか?」 お話:深海ゾーンは「豊富(~80匹)」か「空(~10匹)」、観測にはノイズが乗る。
3つのステップ:コインを投げて H を選ぶ (ベルヌーイ) → 真の平均 μ が決まる → μ の周りでノイズ付き観測 (μ周りのガウス)。
Bayesian inference — invert the arrowベイズ推論 — 矢印を逆向きに
The generative model goes forward:
H → D (pick a zone, then sample fish)
Bayesian inference goes backward:
D → H (saw an observation; which zone produced it?)
Example: you observe 40 fish.
• Under H₁ (rich, μ=80): an obs of 40 is unusual but possible.
• Under H₂ (empty, μ=10): an obs of 40 is also unusual but possible.
• Bayes weighs both → posterior over H.
The forward model gives you P(D \mid H). The backward inversion is what students computed in MP1 — multiply by the prior, normalize, get P(H \mid D).
生成モデルは前向き:
H → D (ゾーンを選び、魚を観測)
ベイズ推論は逆向き:
D → H (観測値があった。どのゾーンから生成された?)
例:40匹を観測した。
• H₁(豊富、μ=80)の下では:40は珍しいが起こりうる。
• H₂(空、μ=10)の下でも:40は珍しいが起こりうる。
• ベイズは両方を重みづけ → Hの事後分布。
前向きモデルからP(D \mid H)。逆向きの反転がMP1でやったこと — 事前分布を掛けて正規化、P(H \mid D)を得る。
Base-rate neglect基準率の無視
Taxicab problem (Tversky & Kahneman, 1972):
Hit-and-run. 85% of cabs are Green, 15% Blue. A witness identifies the cab as Blue and is correct 80% of the time.
Gut answer: P(Blue | witness) ≈ 0.80. Most people stop here.
Bayes:
P(\text{Blue} \mid W) \;=\; \frac{P(W \mid \text{Blue})\;P(\text{Blue})}{P(W \mid \text{Blue})\,P(\text{Blue}) + P(W \mid \text{Green})\,P(\text{Green})}
\frac{\textcolor{#64B5F6}{0.80}\cdot\textcolor{#FFA726}{0.15}}{\textcolor{#64B5F6}{0.80}\cdot\textcolor{#FFA726}{0.15} + \textcolor{#64B5F6}{0.20}\cdot\textcolor{#FFA726}{0.85}} \;=\; \textcolor{#FFEB3B}{0.41}
You forgot the prior — that most (85%) of the cabs are Green. The base rate matters as much as the witness reliability.
MP1: a strong prior + one noisy observation barely moved the posterior.
タクシー問題(Tversky & Kahneman, 1972):
ひき逃げ事件。タクシーの85%が緑、15%が青。目撃者は青と特定し、正解率は80%。
直感的な答え:P(青 | 目撃) ≈ 0.80。 多くの人はここで止まる。
ベイズ:
P(\text{青} \mid W) \;=\; \frac{P(W \mid \text{青})\;P(\text{青})}{P(W \mid \text{青})\,P(\text{青}) + P(W \mid \text{緑})\,P(\text{緑})}
\frac{\textcolor{#64B5F6}{0.80}\cdot\textcolor{#FFA726}{0.15}}{\textcolor{#64B5F6}{0.80}\cdot\textcolor{#FFA726}{0.15} + \textcolor{#64B5F6}{0.20}\cdot\textcolor{#FFA726}{0.85}} \;=\; \textcolor{#FFEB3B}{0.41}
事前確率を忘れていた — そもそも85%のタクシーは緑。基準率は目撃者の信頼性と同じくらい重要。
MP1で経験:強い事前 + 1つのノイズ観測では事後はほとんど動かない。
Up next — Day 1 agenda次はここ — 第1日 アジェンダ
- Tutorial Part 1 — Beliefs → Actionsチュートリアル Part 1 — 信念から行動へ 0:00
- Tutorial Part 3 — Reading Code with AIチュートリアル Part 3 — AIとコードを読む 0:15
- Break休憩 0:35
- From Beliefs to Decisions信念から意思決定へ 0:40
- Bayesian Reasoningベイズ的推論 0:45
- Decision Theory意思決定理論 1:05
- The Normative-Descriptive Gap規範と記述のギャップ 1:30
- Break休憩 1:35
- Tutorial Part 2 — EMA vs Bayesianチュートリアル Part 2 — EMA対ベイズ 1:45
- Tutorial Part 4 — MP2 Demoチュートリアル Part 4 — MP2デモ 2:00
- MP2 Launch + Close課題開始 + クロージング 2:10
Decision Theory — What Should You Do?意思決定理論 — 何をすべきか?
Refresher — the 5 fishing zones from MP1復習 — MP1の5つの釣りゾーン
| zone | prior description | character |
|---|---|---|
| Southern Reef | “40-60, reliable” | steady baseline |
| Eastern Shallows | “50-70, recent activity” | moderately known |
| Western Bay | “could be anything” | wide-open prior |
| Kelp Forest | “20-40, recovering” | outdated prior |
| Deep Water | “sometimes huge (75-95), sometimes empty (15-40)” | bimodal, unpredictable |
We’ll use these names throughout today. Watch for Southern Reef (reliable) vs Deep Water (high-variance) — that contrast carries the rest of Day 1.
| ゾーン | 事前情報 | 性質 |
|---|---|---|
| Southern Reef(南の珊瑚礁) | 「40-60、安定」 | 安定したベースライン |
| Eastern Shallows(東の浅瀬) | 「50-70、最近活動あり」 | やや既知 |
| Western Bay(西の湾) | 「なんとも言えない」 | 幅広い事前 |
| Kelp Forest(藻場) | 「20-40、回復中」 | 古い事前情報 |
| Deep Water(深海) | 「巨大(75-95)か空(15-40)の二極」 | 二峰性、予測困難 |
今日の例ではこれらの名前を一貫して使う。Southern Reef(安定)と Deep Water(高分散)の対比が本日後半を貫く。
Beliefs are not decisions信念は決定ではない
You have posteriors for each zone.
Where do you fish?
A decision rule maps beliefs → actions.
Today: four decision-theoretic concepts you’ll use in MP2:
• Expected utility
• Risk attitudes
• Explore-exploit + ε-greedy
• EMA as a simplified update
各ゾーンの事後分布はある。
どこで釣る?
決定規則は信念 → 行動の写像。
今日扱うのはMP2で使う4つの概念:
• 期待効用
• リスク態度
• 探索-搾取と ε-greedy
• 簡易更新としてのEMA
Action vs outcome行動と結果
You fish Southern Reef for 5 days. Catches: 60, 50, 70, 40, 55.
• Action: fish in Southern Reef — same every day.
• Outcome: 60, 50, 70, 40, 55 — different every day.
Same action, different outcomes. Why? The world is noisy.
Average over 5 days: 55. Pretty good — but no single day was exactly 55.
Southern Reefで5日間釣りをした。漁獲:60, 50, 70, 40, 55。
• 行動:Southern Reefで釣る — 毎日同じ。
• 結果:60, 50, 70, 40, 55 — 毎日違う。
同じ行動、違う結果。なぜ?世界はノイズが乗るから。
5日間の平均:55。まあまあ良い — でもどの日もちょうど55ではなかった。
Expected value — what to expect on average期待値 — 平均して何を予想するか
5 days isn’t much data. With more data, the average stabilizes. The limit is the expected value.
Suppose Southern Reef’s true outcome distribution is:
| outcome (fish) | probability |
|---|---|
| 40 | 10% |
| 50 | 30% |
| 60 | 40% |
| 70 | 20% |
Expected fish per day:
E[\text{fish}] = 0.10 \cdot 40 + 0.30 \cdot 50 + 0.40 \cdot 60 + 0.20 \cdot 70 = 57
Each outcome weighted by how often it happens. That’s all “expected” means.
5日間のデータは少ない。データが増えれば平均は安定する。その極限が期待値。
Southern Reefの真の結果分布が次の通りだったとする:
| 結果(魚) | 確率 |
|---|---|
| 40 | 10% |
| 50 | 30% |
| 60 | 40% |
| 70 | 20% |
1日あたりの期待漁獲量:
E[\text{魚}] = 0.10 \cdot 40 + 0.30 \cdot 50 + 0.40 \cdot 60 + 0.20 \cdot 70 = 57
各結果をそれがどれだけ頻繁に起こるかで重みづけ。それだけ。
Not all fish are equal魚はみな同じではない
Counting fish breaks down when fish are worth different amounts.
Japanese market values (rough wholesale): Tuna ~¥10,000/fish, Sardine ~¥100/fish — a 100× gap.
Two zones, two strategies (on a good day for each):
| zone | catches per day | total daily value |
|---|---|---|
| Southern Reef (sardine school) | 50 sardines | 50 × ¥100 = ¥5,000 |
| Deep Water (good day — high mode) | 27 sardines + 3 tuna | 27·¥100 + 3·¥10,000 = ¥32,700 |
Deep Water on a good day catches fewer fish but earns 6× more.
Counting fish ≠ measuring goodness. We need a function that turns an outcome into a value-to-you.
魚に価値の違いがあると、ただ数えるだけでは足りない。
日本市場の概算卸売価格: マグロ 1匹 約¥10,000、イワシ 1匹 約¥100 — 100倍の差。
2つのゾーン、2つの戦略(各ゾーンの良い日):
| ゾーン | 1日の漁獲 | 1日の総価値 |
|---|---|---|
| Southern Reef(イワシの群れ) | イワシ50匹 | 50 × ¥100 = ¥5,000 |
| Deep Water(良い日 — 高い側) | イワシ27匹 + マグロ3匹 | 27·¥100 + 3·¥10,000 = ¥32,700 |
Deep Waterの良い日は、魚の数は少ないが、収入は6倍。
魚の数を数えるだけでは「良さ」は測れない。結果を「自分にとっての価値」に変換する関数が必要。
The utility function効用関数
A utility function u(\cdot) takes an outcome and returns a number that reflects how much you care. Per fish: u(\text{sardine}) = 100, u(\text{tuna}) = 10{,}000.
Total utility of an outcome o (a bag of fish) — sum the per-fish utilities:
U(o) \;=\; \sum_{f \in o} u(f)
• Southern Reef: U(50\text{ sardines}) = 50 \cdot 100 = \mathbf{5{,}000}
• Deep Water: U(27\text{ sardines} + 3\text{ tuna}) = 27 \cdot 100 + 3 \cdot 10{,}000 = \mathbf{32{,}700}
Compare U, not raw counts. An aquarium with u(\text{tuna}) = 0 would prefer Southern Reef — different u, different best zone.
効用関数u(\cdot)は、結果を「自分にとってどれだけ良いか」の数値に変換する関数。1匹あたり:u(\text{イワシ}) = 100、u(\text{マグロ}) = 10{,}000。
結果o(魚の袋)の合計効用 — 1匹ずつの効用を合計:
U(o) \;=\; \sum_{f \in o} u(f)
• Southern Reef:U(\text{イワシ50匹}) = 50 \cdot 100 = \mathbf{5{,}000}
• Deep Water:U(\text{イワシ27匹} + \text{マグロ3匹}) = 27 \cdot 100 + 3 \cdot 10{,}000 = \mathbf{32{,}700}
比べるのはU、漁獲数ではない。 水族館がu(\text{マグロ})=0ならSouthern Reefが最良 — uが変われば最良ゾーンも変わる。
EU in action — should you buy a lottery ticket?EU実演 — 宝くじを買うべきか?
Setup: A ticket costs ¥100. 5% chance to win ¥5,000.
Two outcomes (relative to your wallet):
• Lose: −¥100 with probability 0.95
• Win: +¥4,900 (¥5,000 prize − ¥100 ticket) with probability 0.05
Expected utility:
E[U] = 0.95 \cdot (-100) + 0.05 \cdot (4{,}900) = -95 + 245 = \mathbf{+150}
Positive EU. By the rule, you should buy. (Though only by ¥150 — small expected gain.)
Most real lotteries: realistic prize-and-probability structures give negative EU. Don’t buy those.
設定:チケット¥100。5%の確率で¥5,000当選。
2つの結果(財布から見て):
• ハズレ:−¥100、確率0.95
• 当選:+¥4,900(¥5,000賞金 − ¥100チケット)、確率0.05
期待効用:
E[U] = 0.95 \cdot (-100) + 0.05 \cdot (4{,}900) = -95 + 245 = \mathbf{+150}
EUは正。ルールに従えば買うべき。(ただし¥150だけ — 期待利益は小さい。)
現実の宝くじ:実際の賞金と確率の構造は負のEUを与えることが多い。それは買わない。
Expected utility — putting it together期待効用 — まとめ
For each action a with outcomes o_i (bags of fish) and probabilities p_i:
EU(a) = \sum_i p_i \cdot U(o_i) \;\;\;\text{where}\;\;\; U(o_i) = \sum_{f \in o_i} u(f)
Decision rule: pick the action with the highest EU.
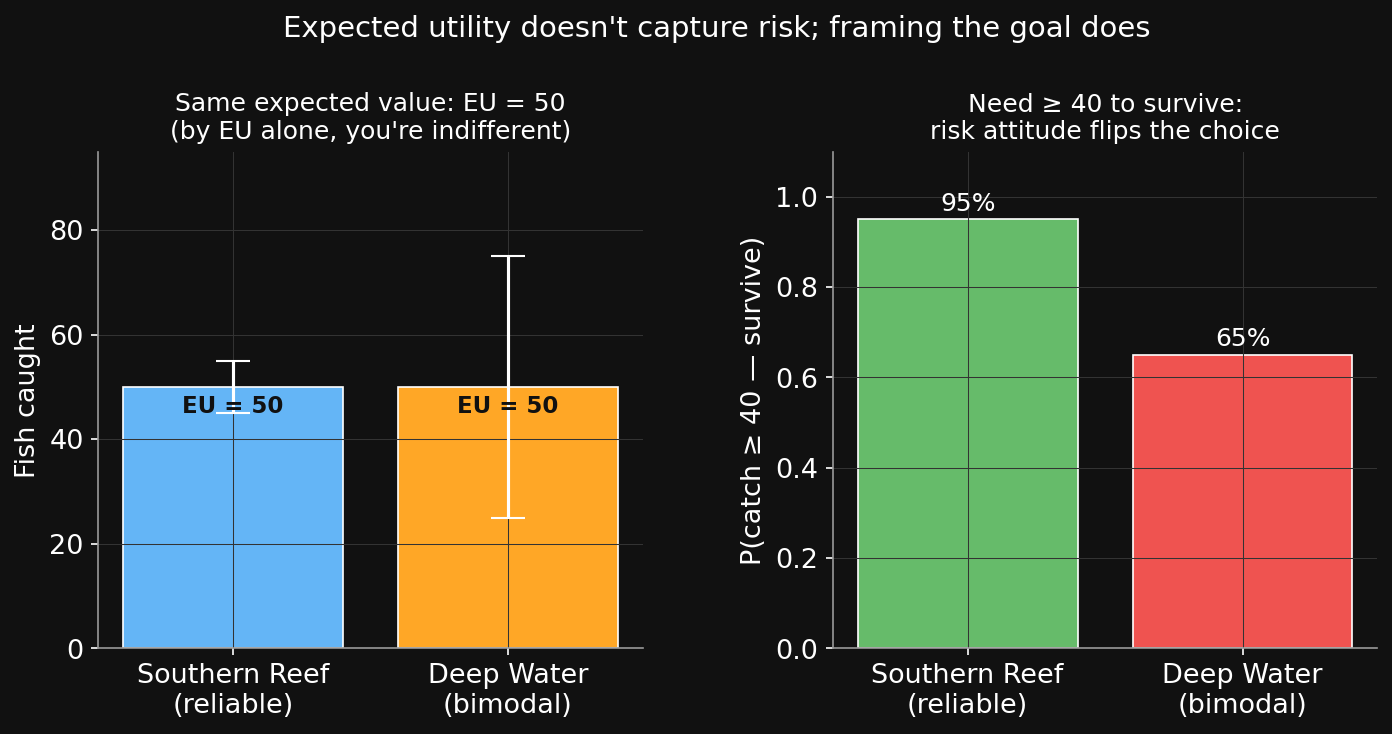
But: EU alone misses something. Suppose the village needs ¥3,000/day to eat tonight.
• Southern Reef: guarantees ¥5,000. Eats every day.
• Deep Water: 50/50 between ¥0 and ¥10,000 (bimodal). Same EU = ¥5,000.
• On Deep Water’s bad day → ¥0. Empty stomachs tonight.
Are you still indifferent?
各行動a、結果o_i(魚の袋)、確率p_iについて:
EU(a) = \sum_i p_i \cdot U(o_i) \;\;\;\text{ただし}\;\;\; U(o_i) = \sum_{f \in o_i} u(f)
決定規則:期待効用が最大の行動を選ぶ。
しかし:EUだけでは足りない。村は今晩食べるのに1日¥3,000必要だとしよう。
• Southern Reef:¥5,000確実。毎日食べられる。
• Deep Water:¥0と¥10,000の半々(二峰性)。EUは同じ¥5,000。
• Deep Waterの悪い日 → ¥0。今晩は空腹。
それでもまだ無差別?
Risk: when variance mattersリスク:分散が効くとき
Explore vs exploit探索 vs 搾取
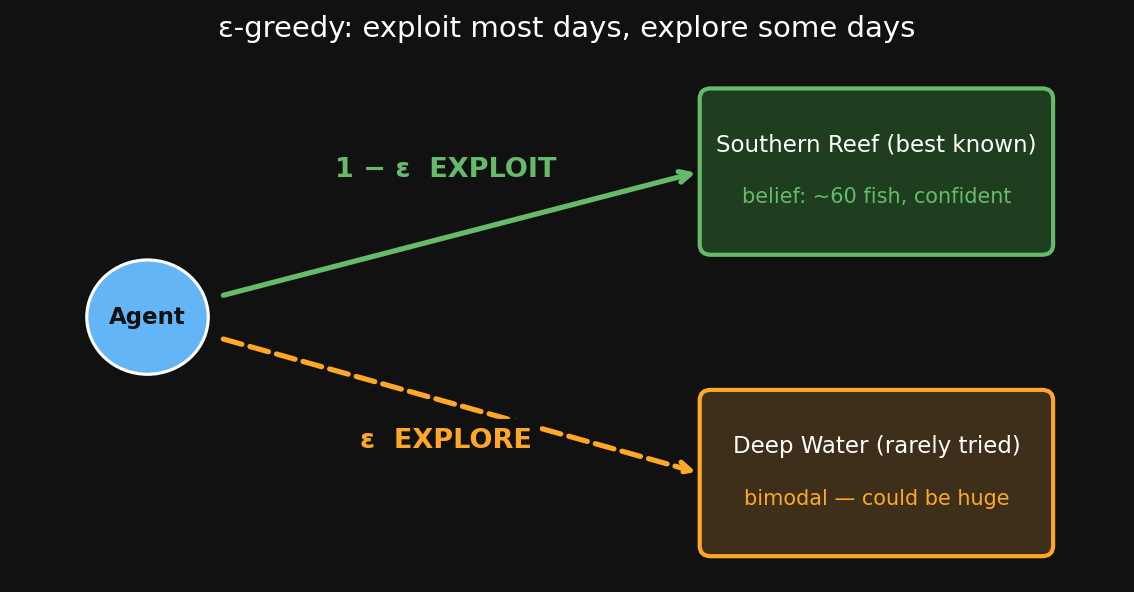
Setup: You’ve fished Southern Reef 10 times (consistent ~60 fish — you’re confident). You’ve fished Deep Water only once and got 30 fish.
Should you try Deep Water again? Not because you think it’s better — but because you don’t yet know which mode it’s in.
Recall: Deep Water’s prior is bimodal — could be ~25 (empty) or ~85 (huge). Your one observation of 30 is consistent with the empty mode… but the huge mode is still on the table.
Exploit = pick the zone you currently believe is best (Southern Reef).
Explore = try a less-known zone to refine your belief (Deep Water).
Your Tutorial Part 1 proposals were exploit-only. The agent needs both.
設定:Southern Reefで10回釣った(一貫して約60匹 — 自信あり)。Deep Waterでは1回だけ釣り、30匹獲れた。
Deep Waterをもう一度試すべきか?「Deep Waterの方が良い」と思うからではなく — まだ二峰性のどちらの側か分からないから。
思い出して:Deep Waterの事前は二峰性 — 約25(空)か約85(巨大)か。1回の観測30は空側と整合的だが、巨大側もまだ排除できない。
搾取(exploit) = 現時点で最良と信じるゾーンを選ぶ(Southern Reef)。
探索(explore) = 情報の少ないゾーンを試して信念を磨く(Deep Water)。
Tutorial Part 1での皆さんの提案は搾取のみだった。エージェントには両方必要。
The ε-greedy ruleε-greedyルール
EMA update — what your agent doesEMA更新 — エージェントの動作
Exponential Moving Average:
\text{new} = \text{old} + \alpha \cdot (\text{obs} - \text{old})
Nudge the belief a fraction \alpha of the way toward the new observation.
Convergence: the mean of the belief tracks truth. Step-to-step fluctuations persist — their size is bounded by \alpha \cdot (observation noise).
• \alpha = 0 — never updates; belief frozen at the prior.
• \alpha small (e.g. 0.1) — slow but steady; tiny fluctuations once near truth.
• \alpha moderate (e.g. 0.3) — balanced; converges in ~5–10 steps, then oscillates within a small band.
• \alpha = 1 — belief = latest observation; no averaging across past obs.
The averaging effect comes from \alpha < 1. Smaller α → smoother but slower; larger α → more responsive but noisier.
指数移動平均(EMA):
\text{new} = \text{old} + \alpha \cdot (\text{obs} - \text{old})
信念を新しい観測に向かって\alphaの割合だけ近づける。
収束:信念の平均が真値を追跡する。ステップごとの揺らぎは残る — その大きさは \alpha \cdot(観測ノイズ)で有界。
• \alpha = 0 — 全く更新しない;信念は事前のまま固定。
• \alpha 小(例:0.1) — 遅いが安定;真値に近づくと揺らぎは微小。
• \alpha 中(例:0.3) — 均衡;5–10ステップで収束し、真値の周りを小さな幅で振動。
• \alpha = 1 — 信念 = 直近の観測;過去の観測を平均化しない。
平均化の効果は \alpha < 1 から生まれる。αが小さいほど滑らかだが遅い;大きいほど反応的だがノイジー。
Worked example — EMA step by stepワーク例 — EMAを一歩ずつ
Setup: zone with true density 70. Tool noise ≈ 10. Four observations: 65, 72, 68, 74.
EMA rule: \text{new} = \text{old} + \alpha \cdot (\text{obs} - \text{old}) with \alpha = 0.3. Start at belief = 50 (“I don’t know”).
Step 1. obs = 65. gap = 65 − 50 = 15. new = 50 + 0.3 × 15 = 50 + 4.5 = 54.5
Step 2. obs = 72. gap = 72 − 54.5 = 17.5. new = 54.5 + 0.3 × 17.5 = 54.5 + 5.25 = 59.75
Step 3. obs = 68. gap = 68 − 59.75 = 8.25. new = 59.75 + 0.3 × 8.25 = 59.75 + 2.475 = 62.23
Step 4. obs = 74. gap = 74 − 62.23 = 11.77. new = 62.23 + 0.3 × 11.77 = 62.23 + 3.53 = 65.76
Each step: gap × α, then add to old belief. After 4 obs, belief = 65.76. Truth = 70. Still ~4 off.
設定:真の密度70のゾーン。ツールのノイズ ≈ 10。4回の観測:65, 72, 68, 74。
EMAルール: \text{new} = \text{old} + \alpha \cdot (\text{obs} - \text{old}) \alpha = 0.3。 信念 = 50(「分からない」)から開始。
ステップ1。 obs = 65。 ギャップ = 65 − 50 = 15。 new = 50 + 0.3 × 15 = 50 + 4.5 = 54.5
ステップ2。 obs = 72。 ギャップ = 72 − 54.5 = 17.5。 new = 54.5 + 0.3 × 17.5 = 54.5 + 5.25 = 59.75
ステップ3。 obs = 68。 ギャップ = 68 − 59.75 = 8.25。 new = 59.75 + 0.3 × 8.25 = 59.75 + 2.475 = 62.23
ステップ4。 obs = 74。 ギャップ = 74 − 62.23 = 11.77。 new = 62.23 + 0.3 × 11.77 = 62.23 + 3.53 = 65.76
各ステップ:ギャップ × α、それを古い信念に足す。4観測後、信念 = 65.76。真値 = 70。まだ約4ずれている。
Same data — Bayes catches up faster同じデータ — ベイズの方が速い
Same 4 observations. Same starting point. Two different methods.
| step | obs | EMA belief | Bayes — mean (std) |
|---|---|---|---|
| 0 | — | 50.00 | 50.00 (28.83) |
| 1 | 65 | 54.50 | 64.99 (9.99) |
| 2 | 72 | 59.75 | 68.50 (7.07) |
| 3 | 68 | 62.23 | 68.33 (5.77) |
| 4 | 74 | 65.76 | 69.75 (5.00) |
After 4 obs: EMA = 65.76 (still ~4 off truth 70). Bayes = 69.75 (essentially on truth) — and reports std 28.83 → 5.00.
Bayes is more powerful with an uninformative prior, but EMA is simpler — often good enough. Next: what does an informative prior buy you?
同じ4観測。同じ出発点。2つの異なる手法。
| ステップ | 観測 | EMA信念 | ベイズ — 平均 (std) |
|---|---|---|---|
| 0 | — | 50.00 | 50.00 (28.83) |
| 1 | 65 | 54.50 | 64.99 (9.99) |
| 2 | 72 | 59.75 | 68.50 (7.07) |
| 3 | 68 | 62.23 | 68.33 (5.77) |
| 4 | 74 | 65.76 | 69.75 (5.00) |
4観測後:EMA = 65.76(真値70からまだ約4ずれ)。ベイズ = 69.75(ほぼ真値ぴったり) — さらに標準偏差は28.83 → 5.00。
事前分布が無情報のときベイズは強力、EMAはシンプル — 多くの問題で十分。次:情報のある事前分布だとどうなる?
What if the prior IS informative?事前分布がある場合は?
Same observations, same noise. Three priors: Uniform (no info), Good (\mathcal{N}(70, 10)), Wrong (\mathcal{N}(30, 10)).
| step | obs | Uniform | Good (μ₀=70) | Wrong (μ₀=30) |
|---|---|---|---|---|
| 0 | — | 50.00 | 70.00 | 30.04 |
| 1 | 65 | 64.99 | 67.50 | 47.50 |
| 2 | 72 | 68.50 | 69.00 | 55.67 |
| 3 | 68 | 68.33 | 68.75 | 58.75 |
| 4 | 74 | 69.75 | 69.80 | 61.80 |
1. A good prior gets you close from step 0 — but uniform catches up by step 2.
2. A wrong prior is overruled by data — slowly. Still 8 off after 4 obs.
3. Data dominates with enough observations. The prior shapes early steps, not the long run.
同じ観測、同じノイズ。3つの事前分布:一様(情報なし)、良い(\mathcal{N}(70, 10))、間違い(\mathcal{N}(30, 10))。
| ステップ | 観測 | 一様 | 良い (μ₀=70) | 間違い (μ₀=30) |
|---|---|---|---|---|
| 0 | — | 50.00 | 70.00 | 30.04 |
| 1 | 65 | 64.99 | 67.50 | 47.50 |
| 2 | 72 | 68.50 | 69.00 | 55.67 |
| 3 | 68 | 68.33 | 68.75 | 58.75 |
| 4 | 74 | 69.75 | 69.80 | 61.80 |
1. 良い事前分布なら最初から真値近く — でも一様もステップ2で追いつく。
2. 間違った事前分布はデータにゆっくり覆される。4観測後でもまだ8ずれている。
3. 観測が十分あればデータが支配する。事前分布は初期を形作るが、長期的には消える。
EMA convergence — three α, three regimesEMAの収束 — 3つのα、3つの挙動
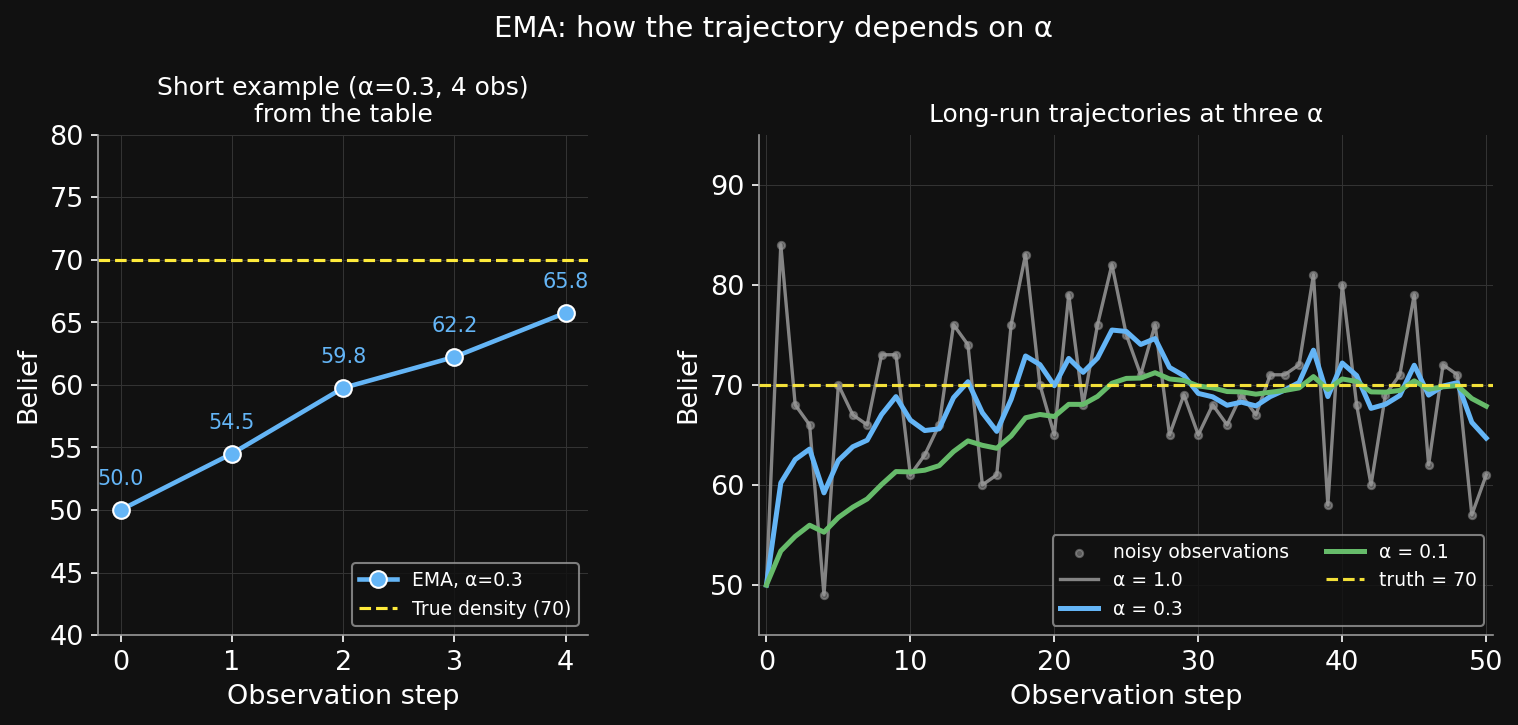
Left: the worked example from the table (α=0.3, 4 obs). Right: 50 noisy observations from the same true density (70), three different α.
• α=0.1 — slow climb, very small fluctuations near truth
• α=0.3 — converges quickly, bounded oscillation
• α=1.0 — belief = latest observation; full noise amplitude
This is what convergence looks like in practice: the mean of the belief tracks truth; the fluctuations shrink to a bounded amplitude that depends on α.
左:表の短い例(α=0.3、4観測)。右:同じ真の密度(70)から50個のノイズ観測、3つの異なるα。
• α=0.1 — 緩やかに上昇、真値近くでは微小な揺らぎ
• α=0.3 — 速やかに収束、有界な振動
• α=1.0 — 信念 = 直近の観測;フルノイズ振幅
実際の収束はこう見える:信念の平均は真値を追跡し、揺らぎはαに応じた有界な振幅まで縮む。
Up next — Day 1 agenda次はここ — 第1日 アジェンダ
- Tutorial Part 1 — Beliefs → Actionsチュートリアル Part 1 — 信念から行動へ 0:00
- Tutorial Part 3 — Reading Code with AIチュートリアル Part 3 — AIとコードを読む 0:15
- Break休憩 0:35
- From Beliefs to Decisions信念から意思決定へ 0:40
- Bayesian Reasoningベイズ的推論 0:45
- Decision Theory意思決定理論 1:05
- The Normative-Descriptive Gap規範と記述のギャップ 1:30
- Break休憩 1:35
- Tutorial Part 2 — EMA vs Bayesianチュートリアル Part 2 — EMA対ベイズ 1:45
- Tutorial Part 4 — MP2 Demoチュートリアル Part 4 — MP2デモ 2:00
- MP2 Launch + Close課題開始 + クロージング 2:10
The Normative-Descriptive Gap規範と記述のギャップ
Humans are not normative agents人間は規範的エージェントではない
Everything I just told you is about how agents SHOULD reason and decide.
But humans DON’T — at least not always.
Day 2 (Thursday):
• Heuristics and biases (representativeness, confirmation)
• Prospect theory (framing, loss aversion, probability weighting)
Is the gap a flaw in human cognition, or a feature?
ここまでは、エージェントがどう推論・決定すべきかという話。
しかし人間はそう動かない — 少なくとも常には。
第2日(木曜):
• ヒューリスティックとバイアス(代表性、確証バイアス)
• プロスペクト理論(フレーミング、損失回避、確率重みづけ)
このギャップは認知の欠陥か、機能か?
Break — 10 minutes休憩 — 10分
Up next — Day 1 agenda次はここ — 第1日 アジェンダ
- Tutorial Part 1 — Beliefs → Actionsチュートリアル Part 1 — 信念から行動へ 0:00
- Tutorial Part 3 — Reading Code with AIチュートリアル Part 3 — AIとコードを読む 0:15
- Break休憩 0:35
- From Beliefs to Decisions信念から意思決定へ 0:40
- Bayesian Reasoningベイズ的推論 0:45
- Decision Theory意思決定理論 1:05
- The Normative-Descriptive Gap規範と記述のギャップ 1:30
- Break休憩 1:35
- Tutorial Part 2 — EMA vs Bayesianチュートリアル Part 2 — EMA対ベイズ 1:45
- Tutorial Part 4 — MP2 Demoチュートリアル Part 4 — MP2デモ 2:00
- MP2 Launch + Close課題開始 + クロージング 2:10
Tutorial Part 2 — EMA vs Bayesian Side-by-Sideチュートリアル Part 2 — EMA vs ベイズ並列比較
Side-by-side並列比較
MP1 (Bayesian):
• posterior[i] = prior[i] * likelihood[i] (then normalize)
• Maintains a full distribution (20 bins)
• Each obs refines the entire shape
MP2 (EMA):
• new = old + α * (obs − old)
• One number per zone (point estimate)
• Each obs nudges the number toward what was observed
Same Marr L1 problem. Different L2 algorithm.
MP1(ベイズ):
• posterior[i] = prior[i] * likelihood[i](その後正規化)
• 完全な分布を保持(20ビン)
• 各観測が分布全体を修正
MP2(EMA):
• new = old + α * (obs − old)
• ゾーンごとに1つの数値(点推定)
• 各観測が観測値の方へ数値を押す
同じMarr L1問題。異なるL2アルゴリズム。
α extremesαの両極
| \alpha | new = | what happens |
|---|---|---|
| 0.0 | 1.0·old + 0.0·obs | never updates |
| 0.1 | 0.9·old + 0.1·obs | steady, prior dominates |
| 0.5 | 0.5·old + 0.5·obs | balanced |
| 1.0 | 0.0·old + 1.0·obs | only the latest obs |
The endpoints are degenerate — α=0 never learns, α=1 forgets everything. Useful α is somewhere in between.
| \alpha | new = | 起こること |
|---|---|---|
| 0.0 | 1.0·old + 0.0·obs | 更新なし |
| 0.1 | 0.9·old + 0.1·obs | 安定、事前に支配 |
| 0.5 | 0.5·old + 0.5·obs | 均衡 |
| 1.0 | 0.0·old + 1.0·obs | 直近の観測のみ |
両端は退化している — α=0は学習しない、α=1は過去を忘れる。有用なαはその間。
Up next — Day 1 agenda次はここ — 第1日 アジェンダ
- Tutorial Part 1 — Beliefs → Actionsチュートリアル Part 1 — 信念から行動へ 0:00
- Tutorial Part 3 — Reading Code with AIチュートリアル Part 3 — AIとコードを読む 0:15
- Break休憩 0:35
- From Beliefs to Decisions信念から意思決定へ 0:40
- Bayesian Reasoningベイズ的推論 0:45
- Decision Theory意思決定理論 1:05
- The Normative-Descriptive Gap規範と記述のギャップ 1:30
- Break休憩 1:35
- Tutorial Part 2 — EMA vs Bayesianチュートリアル Part 2 — EMA対ベイズ 1:45
- Tutorial Part 4 — MP2 Demoチュートリアル Part 4 — MP2デモ 2:00
- MP2 Launch + Close課題開始 + クロージング 2:10
Tutorial Part 4 — MP2 Demoチュートリアル Part 4 — MP2デモ
Live demoライブデモ
Open the correct MP2 simulation in browser.
Three runs to demonstrate:
• ε = 0 — pure exploit (locks onto first decent zone)
• ε = 1 — pure explore (random — never settles)
• ε = 0.1 — balanced (mostly exploits, occasional explore)
Watch the belief panel. Beliefs should converge toward truth over time.
MP2 ships with intentional bugs. Some break this convergence.
ブラウザで正しいMP2シミュレーションを開く。
3つのランを見せる:
• ε = 0 — 純粋な搾取(最初のまずまずのゾーンに固定)
• ε = 1 — 純粋な探索(ランダム — 落ち着かない)
• ε = 0.1 — 均衡(主に搾取、時々探索)
信念パネルを見る。信念は時間と共に真実に収束すべき。
MP2には意図的なバグがある。一部はこの収束を壊す。
What MP2 looks likeMP2の課題内容
You’ll receive a buggy ε-greedy agent. Some bugs are syntax (AI catches). Some are conceptual — like Tutorial Part 3 Bug 3 — where you need MP1-style understanding.
Your job:
1. Run the simulation. Observe the agent’s behavior.
2. Work with AI to read the code and find bugs.
3. Use MP1 understanding to catch what AI misses.
4. Document what you found AND how you found it.
Grading emphasizes WHY a bug is wrong, not just spotting it.
バグだらけのε-greedyエージェントを受け取る。構文バグ(AIが見つける)もあれば、Tutorial Part 3 バグ3のような概念的なものもある — そこではMP1的な理解が必要。
やること:
1. シミュレーションを動かす。エージェントの挙動を観察。
2. AIと一緒にコードを読み、バグを見つける。
3. MP1の理解でAIが見落とすバグを捕まえる。
4. 何を、どうやって見つけたかを記録。
評価は「バグを見つけたか」より「なぜそれがバグか」を重視。
Up next — Day 1 agenda次はここ — 第1日 アジェンダ
- Tutorial Part 1 — Beliefs → Actionsチュートリアル Part 1 — 信念から行動へ 0:00
- Tutorial Part 3 — Reading Code with AIチュートリアル Part 3 — AIとコードを読む 0:15
- Break休憩 0:35
- From Beliefs to Decisions信念から意思決定へ 0:40
- Bayesian Reasoningベイズ的推論 0:45
- Decision Theory意思決定理論 1:05
- The Normative-Descriptive Gap規範と記述のギャップ 1:30
- Break休憩 1:35
- Tutorial Part 2 — EMA vs Bayesianチュートリアル Part 2 — EMA対ベイズ 1:45
- Tutorial Part 4 — MP2 Demoチュートリアル Part 4 — MP2デモ 2:00
- MP2 Launch + Close課題開始 + クロージング 2:10
MP2 Launch + CloseMP2始動 + クロージング
Day 1 close第1日 クロージング
Thursday: heuristics, biases, and prospect theory.
Is the gap between normative and descriptive a flaw in human cognition, or a feature?
Read for Thursday:
• Griffiths, Chater, & Tenenbaum — Ch 1 (continued)
• Wu & Toyokawa — Tutorial 1
Bring MP2 progress notes — we’ll resume debugging discussion.
木曜:ヒューリスティック、バイアス、プロスペクト理論。
規範と記述のギャップは認知の欠陥か、機能か?
木曜までに読むもの:
• Griffiths, Chater, & Tenenbaum — 第1章(続き)
• Wu & Toyokawa — チュートリアル1
MP2の進捗メモを持参 — デバッグ議論を再開する。
Day 2 — The Descriptive Reality第2日 — 記述的な現実
Day 2 Agenda第2日 アジェンダ
- Heuristics and biasesヒューリスティックとバイアス 0:00
- Prospect theoryプロスペクト理論 0:35
- Break休憩 0:55
- Nudging — choice architectureナッジ — 選択アーキテクチャ 1:05
- MP2 in-class workMP2 授業内作業時間 1:35
- MP2 guided discussionMP2 ガイド付き議論 2:28
- Three-week arc + Week 43週間の流れ + 第4週 2:48
- Buffer / Q&A予備 / Q&A 2:56
Why we worked through the mathなぜ数式を一歩ずつ追ったのか
Day 1 was a lot. Bayes. Expected utility. Generative models. EMA. Today is softer — stories, demos, biases you can feel. So why grind through the math?
Without a normative account, there are no biases.
• “People are bad at probability” → bad compared to what?
• “People polarize on the same data” → polarized away from what?
• “People take risks they shouldn’t” → shouldn’t by what standard?
Bayes + EU give us the ruler. Bias must also be systematic — random errors average out; systematic ones predict direction.
Day 1: built the ruler. Day 2: measure the gap. Week 4+ (nudging, MP4): use it to design.
第1日は内容が多かった。ベイズ、期待効用、生成モデル、EMA。今日は柔らかい — 物語、デモ、体感バイアス。ではなぜ数式を追ったのか?
規範的な説明がなければ、バイアスというものは存在しない。
• 「人は確率が苦手」→ 何と比べて苦手?
• 「同じデータで人は極化する」→ 何から離れて極化する?
• 「人はリスクを取りすぎる」→ どの基準で取りすぎ?
ベイズと期待効用がものさしをくれる。さらにバイアスは体系的でなければならない — ランダム誤差は平均で消える、体系的誤差は方向を予測する。
第1日:ものさしを作った。第2日:ズレを測る。第4週以降(ナッジ、MP4):設計に使う。
Heuristics and biasesヒューリスティックとバイアス
Meet Linda — which is more likely?リンダ問題 — どちらが起こりやすい?
Linda is 31, single, outspoken, and very bright. She majored in philosophy. As a student, she was deeply concerned with issues of discrimination and social justice, and also participated in anti-nuclear demonstrations.
Which is more probable?
A. Linda is a bank teller.
B. Linda is a bank teller AND active in the feminist movement.
Pick one. Don’t compute — just say which feels more likely.
リンダは31歳、独身、率直で、非常に頭脳明晰。哲学を専攻していた。学生時代は差別や社会正義の問題に深く関わり、反核デモにも参加していた。
どちらの確率が高いと思う?
A. リンダは銀行員である。
B. リンダは銀行員であり、かつフェミニスト運動に積極的である。
ひとつ選ぶ。計算するのではなく、どちらがより起こりやすいと感じるかを答える。
Linda — the set pictureリンダ — 集合の図

Whatever you believe about how often bank tellers are feminists, the intersection is at most as big as either set. P(A \cap B) \leq P(A), P(A \cap B) \leq P(B).
銀行員とフェミニストの相関について何を信じていても、交わりは各集合より大きくはなれない。 P(A \cap B) \leq P(A)、 P(A \cap B) \leq P(B)。
Linda — the conjunction fallacyリンダ — 連言の誤謬
Most people pick B. But:
P(\text{bank teller} \cap \text{feminist}) \;\leq\; P(\text{bank teller})
The conjunction can never be more likely than its parts. Every Linda-who-is-feminist-and-bank-teller is also a Linda-who-is-bank-teller. B is a subset of A.
The shortcut: rather than computing probability, we substitute an easier question — “how well does B resemble the stereotype of who Linda is?”
The stereotype-match is high for B (philosophy major, discrimination, anti-nuclear) and low for A (just “bank teller”). So B feels more likely — even though it can’t be.
This is representativeness: judging probability by similarity instead of by the math. Sometimes it works. Here it produces a logical contradiction.
多くの人はBを選ぶ。しかし:
P(\text{銀行員} \cap \text{フェミニスト}) \;\leq\; P(\text{銀行員})
連言(かつ)の確率は、その要素単独の確率を絶対に超えない。リンダが銀行員かつフェミニストなら、必ず銀行員でもある。BはAの部分集合。
ショートカット:確率を計算する代わりに、より簡単な問いに置き換える — 「Bはリンダのステレオタイプにどれだけ似ているか?」
ステレオタイプ一致度は、Bは高い(哲学専攻・差別・反核)、Aは低い(単に「銀行員」)。だからBの方が起こりやすく感じる — 論理的にはあり得ないのに。
これが代表性ヒューリスティック:確率を数学ではなく類似度で判断する。うまくいくこともある。ここでは論理的矛盾を生む。
Representativeness in the wild — the dot-com bubble現実の代表性 — ドットコムバブル
Late-1990s stock market (Cooper et al., 2001, 2005):
• Pre-bubble: companies with “.com” in their name (or that added “.com”) rose in value — regardless of any actual Internet business.
• Post-bubble: companies that removed “.com” from their name rose in value.
The substitution: “looks like a tech company” → “is a winner.”
Investors weren’t computing P(success | financials, market). They were resemble-matching to the stereotype of “this is the future.” Same shortcut as Linda — bigger numbers.
MP2 link: “looks like a learning algorithm” → “is correct.” The buggy EMA formula old + α·obs resembles a real update rule. AI may agree because the form matches. You catch it because you ran the trace and saw beliefs blow up.
1990年代後半の株式市場(Cooper et al., 2001, 2005):
• バブル前:社名に「.com」を含む(または追加した)会社の株価は上昇 — インターネット事業との実質的な関係があるかは問わない。
• バブル後:社名から「.com」を取り除いた会社の株価は上昇。
置き換え:「テック企業っぽく見える」→「勝者である」。
投資家はP(成功 | 財務、市場)を計算していなかった。「これが未来だ」というステレオタイプに対する類似度マッチングをしていた。リンダ問題と同じショートカット — ただし数字の桁が違う。
MP2との関連:「学習アルゴリズムっぽく見える」→「正しい」と判断。バグスニペットのold + α·obsは本物の更新式に似ている。AIも形式が一致するので同意してしまうかもしれない。皆さんが気づくのは、トレースして信念が爆発するのを見たから。
Representativeness in hiring & tenure代表性 — 採用と昇進
Steinpris, Anders & Ritzke (1999): Same CV, name swapped to signal gender, sent to faculty hiring/tenure reviewers.
• “Standard” CV → male preferred. Rated more likely to get job/tenure.
• “Stellar” CV → gender played no role. Reviewer’s own gender didn’t matter.
Chen et al. (2018): 855,000 candidates on a major resume-search platform. Feminine names ranked lower by recruiters — even controlling for credentials.
The substitution: “looks like a professor / engineer / leader” → “is qualified.” Representativeness is doing the work; the stereotype is doing the harm.
Why it matters: the bias only fades when credentials are undeniably outstanding. For the median candidate, representativeness shapes who gets the chance.
Steinpris, Anders & Ritzke (1999):同じ履歴書、性別を示唆する名前だけ変更、教員採用・昇進審査員に送付。
• 「標準的」な履歴書 → 男性候補が好まれた。採用・昇進の可能性も高評価。
• 「卓越した」履歴書 → 性別の影響なし。審査員自身の性別も関係なかった。
Chen et al. (2018):85万5千件の候補者データ。資格を統制しても、女性的な名前はリクルーターに低くランク付けされた。
置き換え:「教授/エンジニア/リーダーっぽく見える」→「資格がある」と判断。代表性が働き、ステレオタイプが害を生む。
なぜ重要か:資格が圧倒的に優れているときだけバイアスは消える。中央値の候補者では、代表性が「チャンスを得る人」を決めている。
Memorize these namesこれらの名前を覚えてください
I’ll show you 12 names, one at a time.
Try to remember as many as you can — I’ll ask you about them in a minute.
これから12人の名前を1人ずつ見せます。
できるだけ多く覚えてみてください — 後で質問します。
Ohtani Shohei大谷翔平
Jessica Tannerジェシカ・タナー
Murakami Haruki村上春樹
Tanaka Yuki田中由紀
Elon Muskイーロン・マスク
Sarah Mitchellサラ・ミッチェル
Sakamoto Ryuichi坂本龍一
Nakamura Aiko中村愛子
Cristiano Ronaldoクリスティアーノ・ロナウド
Emily Brooksエミリー・ブルックス
Miyazaki Hayao宮崎駿
Kobayashi Misaki小林美咲
Were there more men or more women?男性と女性、どちらが多かった?
Don’t look back. Commit to an answer.
• More men
• More women
Show of hands. Forced choice — pick one.
振り返らずに。答えを決めてください。
• 男性が多い
• 女性が多い
挙手で。強制選択 — どちらか必ず選ぶ。
It was 6 and 66対6でした
Equal. 6 men, 6 women.
The men you remembered were famous — Ohtani, Murakami, Musk, Sakamoto, Ronaldo, Miyazaki. The women weren’t.
You judged “how many?” by how easily examples came to mind. That’s the availability heuristic — and your memory was biased by fame, not frequency.
同数。男性6人、女性6人。
覚えていた男性は有名人 — 大谷、村上、マスク、坂本、ロナウド、宮崎。女性はそうではなかった。
皆さんは「どれだけ多い?」をどれだけ簡単に例を思い浮かべられるかで判断した。それが利用可能性ヒューリスティック — 記憶が頻度ではなく知名度に偏っていた。
Availability — what comes to mind first利用可能性 — 思い浮かびやすさ
Heuristic: judge “how likely?” by how easy is it to bring examples to mind?
Often correct (memory tracks frequency). But biased when memory is biased.
Tversky & Kahneman (1973): the original study — subjects shown lists of names, asked “more men or more women?”
• Lists where the men were famous and the women weren’t → judged more men.
• Lists where the women were famous and the men weren’t → judged more women.
Actual count was equal. Famous names are easier to recall → judged more frequent. (You just lived this.)
MP2 link: when AI proposes a fix, you’ll judge it by the kind of fix you’ve seen work before. If you’ve recently fixed three off-by-one bugs, you’ll over-look for off-by-ones. Conceptual bugs (like our wrong-EMA) are less available in memory → harder to spot.
ヒューリスティック:「どれだけ起こりやすい?」をどれだけ簡単に例を思い浮かべられるかで判断。
多くの場合は正しい(記憶は頻度を追跡する)。しかし記憶に偏りがあれば、判断にも偏りが出る。
Tversky & Kahneman (1973):元の研究 — 被験者に名前のリストを見せ、「男性と女性、どちらが多い?」と質問。
• 男性は有名人、女性は無名 → 男性が多いと判断。
• 女性が有名人、男性が無名 → 女性が多いと判断。
実際の数は同数。有名な名前は思い出しやすい → 多く感じる。(皆さんが今体験したこと。)
MP2との関連:AIが修正を提案したとき、皆さんは過去に見た「うまくいった修正」のタイプで判断する。最近off-by-oneを3つ直したら、off-by-oneを過剰に探す。概念的バグ(例:誤ったEMA)は記憶上利用しにくい → 見落としやすい。
Confirmation bias確証バイアス
Tendency to seek and overweight evidence that confirms existing beliefs.
MP2 link:
AI suggests a fix. You run the code. It doesn’t crash.
“It works!”
But does it work correctly? You looked for confirming evidence and stopped.
This is why students typically need 4-5 debugging cycles, not 1.
既存の信念を裏付ける証拠を探し、過大に重み付けする傾向。
MP2との関連:
AIが修正を提案。コードを動かす。クラッシュしない。
「動いた!」
でも正しく動いたのか?確証する証拠だけ見て止めた。
だから学生は通常1回ではなく4-5サイクルのデバッグが必要。
Confirmation bias in the wild現実の確証バイアス
Lord, Ross & Lepper (1979) — biased assimilation: pro- and anti-capital-punishment subjects given the same mixed evidence (one pro-deterrent study, one anti-).
Result: each group became more polarized. Pro-subjects rated the pro-study well-done and the anti-study flawed. Anti-subjects: opposite. Replicated across climate, guns, vaccines, GMOs.
Try it: nuclear power post-Fukushima. Same TEPCO report. Pro-restart camps see “manageable risk, lessons learned.” Anti-restart camps see “uncontrollable consequences, regulatory failure.” Same evidence, opposite conclusions.
Why “more data” doesn’t fix disagreements: people filter.
Lord, Ross & Lepper (1979) — 偏った同化:死刑賛成派と反対派に同じ混合証拠を与えた(賛成側1本、反対側1本)。
結果:両グループともさらに極化した。 賛成派は賛成研究を「よくできている」、反対研究を「欠陥あり」と評価。反対派は逆。気候、銃、ワクチン、GMOで再現済み。
自分で試そう:福島後の原発問題。 同じTEPCO報告書。再稼働賛成派は「管理可能なリスク、教訓あり」、反対派は「制御不能、規制の失敗」と読む。同じ証拠、正反対の結論。
「もっとデータがあれば」では対立は解消しない。 人はフィルターをかける。
The fix — “Consider the Opposite”対処法 — 「逆を考える」
Lord, Lepper & Preston (1984): can we prevent the polarization? Two interventions tested:
• “Be unbiased” (“evaluate fairly, like a juror”) → barely helped.
• “Consider the opposite” (“would you evaluate the same if the study produced opposite results?”) → nearly eliminated the bias.
US judges routinely ask compromised jurors “can you set aside your beliefs and be impartial?” Saying “yes” doesn’t reduce bias — it’s the wrong question.
MP2 application — when AI proposes a fix:
“If this fix produced the opposite behavior — beliefs swinging wildly instead of converging — would I still call it correct?”
That’s critical reasoning in action. Use it.
Lord, Lepper & Preston (1984):極化を防げるか?2つの介入を試した:
• 「公平に判断して」(「裁判員のように評価して」)→ ほとんど効果なし。
• 「逆を考える」(「同じ研究が逆の結果を出していたら、同じ評価をしただろうか?」)→ ほぼバイアスを消した。
米国の裁判官は陪審員候補に「自分の信念を脇に置いて公平に判断できますか?」と尋ねる。「はい」と答えてもバイアスは減らない — 質問が間違っている。
MP2への応用 — AIが修正を提案したら:
「この修正が逆の挙動を生んだら — 信念が収束するのではなく激しく振動したら — それでも正しいと言えるだろうか?」
これが批判的思考の実践。使って。
Quick — what’s your gut answer?直感で答えて
Three questions. Gut answer only. ~90 seconds.
1. A bat and a ball cost ¥110 in total. The bat costs ¥100 more than the ball. How much does the ball cost?
2. If it takes 5 machines 5 minutes to make 5 widgets, how long would it take 100 machines to make 100 widgets?
3. A patch of lily pads in a lake doubles in size every day. If it takes 48 days to cover the entire lake, how long until it covers half?
Don’t compute. Don’t share yet. Write down your first answer.
3つの問題。直感で答えて。約90秒。
1. バットとボールの合計は¥110。バットはボールより¥100高い。ボールはいくら?
2. 5台の機械が5分で5個の部品を作るなら、100台の機械が100個の部品を作るのに何分かかる?
3. 湖の蓮の葉が毎日2倍に広がる。48日で湖全体を覆うなら、半分を覆うのに何日?
計算しない。まだ共有しない。最初に浮かんだ答えを書く。
System 1 vs System 2システム1 vs システム2
Answers:
1. Bat-and-ball: ball = ¥5, bat = ¥105. (Gut: ¥10.)
2. Widgets: 5 minutes. (Each machine makes one widget in 5 min. Gut: 100.)
3. Lily pad: 47 days. (Doubling — the day before is half. Gut: 24.)
System 1 — fast, intuitive, automatic. Pattern-matches. Gave you the wrong answers.
System 2 — slow, deliberative, effortful. Notices when the pattern breaks.
Frederick (2005), Cognitive Reflection Test. ~80% of elite-undergrad subjects miss at least one; many miss all three.
MP2 link — System 1: “AI fixed it, looks good, move on.” System 2: “Wait — let me trace the belief and see if it actually converges.”
The entire point of MP2 is to train your System 2 for AI collaboration. Every gut answer is a place where System 1 took the wheel.
答え:
1. バットとボール:ボール = ¥5、バット = ¥105。(直感:¥10)
2. 部品:5分。(各機械は5分で1個作る。直感:100)
3. 蓮の葉:47日。(2倍 — 全面の前日が半分。直感:24)
システム1 — 速い、直感的、自動的。パターンマッチング。間違った答えをくれた。
システム2 — 遅い、熟慮的、努力を要する。パターンが破綻したことに気づく。
Frederick (2005), 認知反射テスト。一流大学生の約80%が少なくとも1問間違える。3問全部間違える人も多い。
MP2との関連 — システム1:「AIが直した、よさそう、次へ」 システム2:「待って — 信念をトレースして本当に収束するか確認しよう」
MP2の核心は、AI協働のためのシステム2を鍛えること。直感で答えた瞬間、システム1が運転席に座っていた。
Up next — Day 2 agenda次はここ — 第2日 アジェンダ
- Heuristics and biasesヒューリスティックとバイアス 0:00
- Prospect theoryプロスペクト理論 0:35
- Break休憩 0:55
- Nudging — choice architectureナッジ — 選択アーキテクチャ 1:05
- MP2 in-class workMP2 授業内作業時間 1:35
- MP2 guided discussionMP2 ガイド付き議論 2:28
- Three-week arc + Week 43週間の流れ + 第4週 2:48
- Buffer / Q&A予備 / Q&A 2:56
Prospect theoryプロスペクト理論
Framing — the sinking ship problemフレーミング — 沈没船問題
A ship is sinking. 600 people will die unless rescued. Two rescue plans:
Frame A (gains):
• Plan A: 200 will be saved.
• Plan B: 1/3 chance all 600 saved, 2/3 chance no one saved.
Most pick A. (Risk-averse for gains.)
Frame B (losses):
• Plan C: 400 will die.
• Plan D: 1/3 chance no one dies, 2/3 chance all 600 die.
Most pick D. (Risk-seeking for losses.)
Same outcomes. Different frame. Different choice.
船が沈没しつつある。救助しなければ600人が亡くなる。2つの救助計画:
フレームA(利得):
• 計画A:200人を助ける。
• 計画B:1/3の確率で600人全員救助、2/3の確率で誰も救えない。
多くはAを選ぶ。(利得ではリスク回避。)
フレームB(損失):
• 計画C:400人が亡くなる。
• 計画D:1/3の確率で誰も亡くならない、2/3の確率で全員亡くなる。
多くはDを選ぶ。(損失ではリスク追求。)
結果は同じ。フレームが違うだけ。選択が変わる。
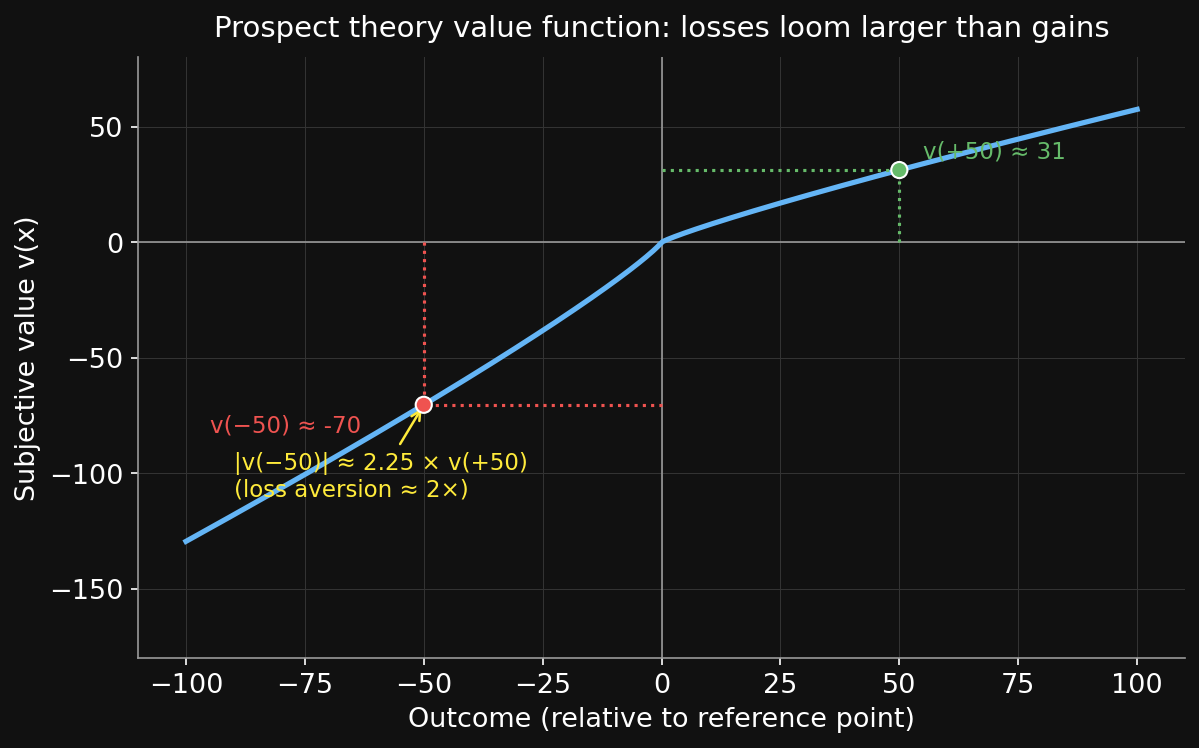
Loss aversion + the value function損失回避と価値関数
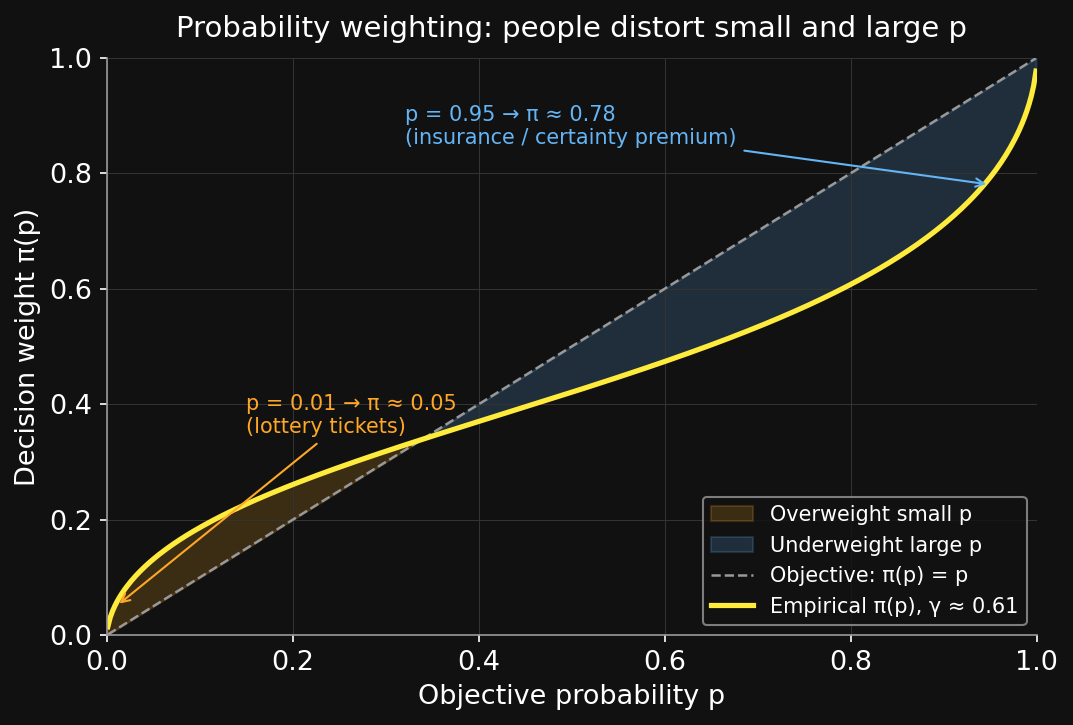
Probability weighting確率重みづけ
Prospect theory — the equationプロスペクト理論 — 式
Expected utility (the normative model):
EU(L) = \sum_i p_i \cdot u(x_i)
Prospect theory (the descriptive model):
V(L) = \sum_i \pi(p_i) \cdot v(x_i)
Same shape. Two substitutions: objective probability p → subjective weight \pi(p); objective value u(x) → subjective value v(x) relative to a reference point.
The claim: humans still aggregate probability × value — just not the probabilities and values you’d expect.
Kahneman won the 2002 Nobel Prize in Economics for this. (Tversky had died in 1996; the prize isn’t awarded posthumously.)
期待効用(規範モデル):
EU(L) = \sum_i p_i \cdot u(x_i)
プロスペクト理論(記述モデル):
V(L) = \sum_i \pi(p_i) \cdot v(x_i)
形は同じ。2つの置き換え:客観確率 p → 主観的重み \pi(p);客観的価値 u(x) → 参照点に対する主観的価値 v(x)。
主張:人間はやはり確率×価値で集計する — ただし想定される確率や価値ではない。
カーネマンは2002年にノーベル経済学賞を受賞(トヴェルスキーは1996年に死去;ノーベル賞は死後には授与されない)。
Closing the prospect-theory loopプロスペクト理論のまとめ
The picture from today so far:
• Humans use heuristics — fast shortcuts that sometimes mislead.
• Framing flips preferences. Losses hurt ~2× more than gains feel good.
• Confirmation bias makes more data make things worse.
So what do we do?
Two options:
1. Debias people — teach them, train them, ask them to be careful. Mostly doesn’t work (Lord/Lepper/Preston “be unbiased” intervention from earlier today).
2. Redesign the choice environment. — meet people where they are. This is what nudging does — coming up after the break.
今日ここまでの全体像:
• 人間はヒューリスティックを使う — 時に誤らせる速いショートカット。
• フレーミングは選好を反転させる。損失は同等の利得よりも約2倍痛い。
• 確証バイアスは、データが増えるほど状況を悪化させる。
ではどうするか?
2つの選択肢:
1. 人をバイアス除去する — 教える、訓練する、慎重になるよう求める。ほとんど機能しない(今日の前半で扱ったLord/Lepper/Preston「公平に判断して」介入)。
2. 選択環境を再設計する。— 人をありのまま受け入れる。これがナッジ — 休憩後に扱う。
Break — 10 minutes休憩 — 10分
Up next — Day 2 agenda次はここ — 第2日 アジェンダ
- Heuristics and biasesヒューリスティックとバイアス 0:00
- Prospect theoryプロスペクト理論 0:35
- Break休憩 0:55
- Nudging — choice architectureナッジ — 選択アーキテクチャ 1:05
- MP2 in-class workMP2 授業内作業時間 1:35
- MP2 guided discussionMP2 ガイド付き議論 2:28
- Three-week arc + Week 43週間の流れ + 第4週 2:48
- Buffer / Q&A予備 / Q&A 2:56
Nudging — choice architectureナッジ — 選択アーキテクチャ
There is no neutral menu中立的なメニューは存在しない
A school cafeteria has to put something first in the lunch line.
• Pizza first → students grab pizza.
• Salad first → students grab salad.
Someone has to decide what comes first.
The question is not “should we influence?” — that’s already happening, no matter what you do.
The question is “how should we influence?”
Thaler & Sunstein (2008): choice architecture is the way options are presented. Nudging = designing the architecture to steer choices toward better outcomes — without restricting them.
学校のカフェテリアは、ランチの列に何かを最初に置かなければならない。
• ピザを最初に → 学生はピザを取る。
• サラダを最初に → 学生はサラダを取る。
誰かが「何を最初に置くか」を決めなければならない。
問いは「影響を与えるべきか?」ではない — 何をしても影響は既に起きている。
問いは「どう影響を与えるべきか?」
Thaler & Sunstein (2008):選択アーキテクチャとは選択肢の提示の仕方。ナッジは、選択を制限せずに、より良い結果へ向けるアーキテクチャの設計。
What is a nudge?ナッジとは?
A nudge steers without restricting. You can still pick anything; the architecture just makes some choices easier.
Six families (Sunstein 2017):
1. Just-in-time info — GPS reroutes; “you’ve had 800 cal today”
2. Mandatory info — cigarette warnings; energy-efficiency labels
3. Defaults & opt-in/opt-out — organ donor checkboxes; 401(k) auto-enroll
4. Visual attention & effort — what’s at eye level; what’s two clicks away
5. Social norms — “9 out of 10 hotel guests reuse towels”
6. Active / forced choice — “you must select a retirement plan to continue”
We’ll look at three: defaults, the cafeteria, and active choice.
ナッジは制限せずに方向づける。何でも選べるけど、アーキテクチャによって特定の選択がやりやすくなる。
6つの分類(Sunstein 2017):
1. タイムリーな情報 — GPSの経路変更;「今日800kcal摂取した」
2. 義務的情報 — タバコの警告;省エネ性能ラベル
3. デフォルトとオプトイン/アウト — 臓器提供のチェック欄;401(k)自動加入
4. 視覚的注意と労力 — 何が目の高さにあるか;何が2クリック先にあるか
5. 社会規範 — 「ホテル客の10人中9人がタオルを再利用」
6. 能動的/強制的選択 — 「次へ進むには年金プランを選択してください」
今日は3つ見る:デフォルト、カフェテリア、能動的選択。
Defaults — organ donation, Japan vs Europeデフォルト — 臓器提供、日本 vs 欧州
Same people. Same preferences. Different forms.
| Country | System | Donor rate |
|---|---|---|
| Austria, France, Spain, Belgium | opt-out | 85–99% |
| Germany, UK (historical) | opt-in | ~10–25% |
| Japan | opt-in (+ family veto) | ~12% |
Expressed-preference studies show similar populations have similar willingness to donate. The form did the deciding — not the values.
Why: filling forms is costly (default wins by inaction); defaults signal social norms; defaults relieve an emotionally hard decision.
同じ人々。同じ選好。異なる書式。
| 国 | 制度 | 提供率 |
|---|---|---|
| オーストリア、フランス、スペイン、ベルギー | オプトアウト | 85–99% |
| ドイツ、英国(過去) | オプトイン | ~10–25% |
| 日本 | オプトイン(+家族拒否権) | ~12% |
表明された選好の調査では、各国の人々の提供したい気持ちは実は似ている。決めているのは書式、価値観ではない。
なぜ:書式記入はコストが高く、デフォルトは何もしないことで勝つ;デフォルトは社会規範を示す;感情的に難しい決定の負担を和らげる。
Cafeteria layout — kyūshoku as choice architectureカフェテリア配置 — 給食という選択アーキテクチャ
The cafeteria experiment (Just & Wansink, 2009): Move fruit to the front, replace soda with water — keep fries available for those who want them.
• 21% fewer calories per meal, 44% less fat, 43% less salt
Same children. Same prices. Same options. Different layout.
Japan already does this — at scale. Kyūshoku (給食) is a national nutrition program: balanced portions, no choice menus, eaten with the teacher. Japan’s school-age obesity rate is among the OECD’s lowest — kyūshoku is one cited reason.
The lesson: when you take design seriously, you use these effects deliberately. When you don’t, you get them anyway — without choosing the direction.
カフェテリア実験(Just & Wansink, 2009):フライドポテトをフルーツに替えて列の前に、コーラを水に替える — ポテトはまだ取れる。
• カロリー21%減、脂質44%減、塩分43%減
同じ子供たち。同じ価格。同じ選択肢。違うのは配置だけ。
日本はすでにこれを大規模にやっている。 給食は国家設計の栄養プログラム:バランスの取れた量、選択メニューなし、先生と一緒に食べる。日本の学齢期肥満率はOECD最低水準 — 給食はその理由の一つ。
教訓:設計を真剣に取り組めば、これらの効果を意図的に使える。取り組まなければ、効果は出るが、方向は選べない。
Retirement defaults — the iDeCo gap退職金デフォルト — iDeCoの隔たり
Madrian & Shea (2001) — US retirement plans:
| System | After 3 months | After 3 years |
|---|---|---|
| Opt-in (active enrollment required) | 20% | 65% |
| Opt-out (automatic enrollment) | 90% | 98% |
Same employees. Same plan. Same incentive. The default carries ~70 percentage points.
Japan’s iDeCo: strong tax incentives, available to nearly all working adults since 2017. Actual participation: ~3%. The friction is active choice — strong incentives lose to do-nothing.
Could we just educate people instead? Duflo & Saez (2003): randomized info intervention → ~1pp. Defaults → ~70pp. Education is the first instinct; rarely the working one.
Madrian & Shea (2001) — 米国の年金プラン:
| 制度 | 3ヶ月後 | 3年後 |
|---|---|---|
| オプトイン(能動的加入が必要) | 20% | 65% |
| オプトアウト(自動加入) | 90% | 98% |
同じ従業員。同じプラン。同じインセンティブ。デフォルトが約70パーセンテージポイントを動かす。
日本のiDeCo:強い税制優遇、2017年以降ほぼ全ての勤労者が利用可能。実際の加入率:約3%。 摩擦は能動的選択 — 強いインセンティブでも何もしないに負ける。
ただ教育すれば? Duflo & Saez (2003):無作為化情報介入は約1pp、デフォルトは約70pp。教育は最初の直感だが、ほぼ機能しない。
Be your own choice architect自分の選択アーキテクトになる
You learned about these biases in others. They operate on you too. Some applied advice from today’s lecture:
• Automate the things you’d procrastinate on. Set up automatic transfers to savings/investments on payday. Removes the daily choice point where present-bias wins.
• Pick a low-cost index fund and don’t touch it. Active funds underperform on average — you’d know that if availability weren’t biasing you toward the success stories you’ve heard about.
• Don’t check your portfolio daily. Loss aversion makes daily fluctuations hurt 2× more than they help. Monthly is plenty; annual is fine.
• Sleep on big purchases. System 2 needs time. The thing you “definitely” want at midnight is rarely the thing you want a week later.
Choice architecture is not just for governments. You can build it for yourself.
今日の講義で他人のバイアスを学んだ。それは皆さん自身にも働く。今日の内容を自分の生活に活かす:
• 先延ばしにしてしまうことは自動化する。給料日に貯蓄・投資への自動振込を設定。現在バイアスが勝つ日々の選択点を取り除く。
• 低コストのインデックスファンドを選び、触らない。アクティブ運用は平均すれば指数に負ける — 利用可能性バイアスが成功例ばかりを目立たせていなければ気付くはず。
• ポートフォリオを毎日チェックしない。損失回避により、日々の変動は嬉しさの2倍痛い。月次で十分、年次でも問題ない。
• 大きな買い物は一晩寝かせる。システム2には時間が必要。深夜に「絶対欲しい」物は、一週間後にはほぼ欲しくない。
選択アーキテクチャは政府だけのものではない。自分自身のために設計できる。
Up next — Day 2 agenda次はここ — 第2日 アジェンダ
- Heuristics and biasesヒューリスティックとバイアス 0:00
- Prospect theoryプロスペクト理論 0:35
- Break休憩 0:55
- Nudging — choice architectureナッジ — 選択アーキテクチャ 1:05
- MP2 in-class workMP2 授業内作業時間 1:35
- MP2 guided discussionMP2 ガイド付き議論 2:28
- Three-week arc + Week 43週間の流れ + 第4週 2:48
- Buffer / Q&A予備 / Q&A 2:56
MP2 in-class workMP2 授業内作業時間
Work it through作業時間
~50 minutes. Continue debugging MP2.
• Use AI freely. But you must be able to explain WHY each bug is wrong — not just that AI flagged it.
• Trace at least one belief update by hand before trusting AI’s read.
• Talk to a neighbor when you find something interesting — but the debugging is yours.
Joe and Ira will circulate. Flag us if you’re stuck — but try the opposite question first (“if AI’s fix were wrong, how would I know?”).
We’ll regroup in ~50 min for a guided discussion of what you found.
約50分。MP2のデバッグを続ける。
• AIは自由に使ってよい。ただし、各バグがなぜ間違いかを説明できなければならない — AIが指摘したからではなく。
• AIの読解を信頼する前に、少なくとも1つの信念更新を手計算でたどる。
• 何か面白いことを見つけたら隣の人と話してよい — でもデバッグは自分の仕事。
ジョー先生とアイラ先生が巡回する。詰まったら声をかけて — でもまず逆の問いを試して(「AIの修正が間違いだったら、どう気づくか?」)。
約50分後にガイド付き議論で集合 — 何を見つけたかを共有。
Up next — Day 2 agenda次はここ — 第2日 アジェンダ
- Heuristics and biasesヒューリスティックとバイアス 0:00
- Prospect theoryプロスペクト理論 0:35
- Break休憩 0:55
- Nudging — choice architectureナッジ — 選択アーキテクチャ 1:05
- MP2 in-class workMP2 授業内作業時間 1:35
- MP2 guided discussionMP2 ガイド付き議論 2:28
- Three-week arc + Week 43週間の流れ + 第4週 2:48
- Buffer / Q&A予備 / Q&A 2:56
MP2 guided discussionMP2 ガイド付き議論
Group conversationグループ討論
Each of you, one bug:
• What was it?
• How did you notice?
• Did AI help, hurt, or miss?
Then we’ll talk together about the hardest bug — what did it take to catch?
Closing question — propose a pattern:
*“AI is good at catching . AI is bad at catching . The reason is ___.”*
一人ずつ、バグ1つ:
• 何だった?
• どう気づいた?
• AIは助けた?妨げた?見逃した?
次にグループで最も難しかったバグについて話す — 何があれば気づけたか?
締めの問い — パターンを提案する:
*「AIは_を見つけるのが得意。AIは_を見逃しがち。理由は___。」*
Up next — Day 2 agenda次はここ — 第2日 アジェンダ
- Heuristics and biasesヒューリスティックとバイアス 0:00
- Prospect theoryプロスペクト理論 0:35
- Break休憩 0:55
- Nudging — choice architectureナッジ — 選択アーキテクチャ 1:05
- MP2 in-class workMP2 授業内作業時間 1:35
- MP2 guided discussionMP2 ガイド付き議論 2:28
- Three-week arc + Week 43週間の流れ + 第4週 2:48
- Buffer / Q&A予備 / Q&A 2:56
Three-week arc3週間の流れ
Where we’ve beenこれまでの流れ
Week 1 — Why should we care?
Plurality: technology and democracy are drifting apart. The path forward isn’t centralized AI or atomized markets — it’s digital democracy, technology that strengthens diverse social connections.
Week 2 — How do agents perceive?
Through their Umwelt — the noisy, partial slice of the world a particular agent can sense. Marr’s levels (computation / algorithm / implementation) let us analyze the same agent at different scales.
Week 3 — How do agents reason and decide?
• Normatively: Bayes + expected utility
• Descriptively: heuristics, biases, prospect theory
• The gap is where design lives.
第1週 — なぜ気にするのか?
Plurality:テクノロジーと民主主義が乖離している。進むべき道は中央集権的AIでも分断された市場でもなく、デジタル民主主義 — 多様な社会的繋がりを強めるテクノロジー。
第2週 — エージェントはどう知覚するのか?
環世界(Umwelt)を通して — エージェントが感知できる、ノイズが多く部分的な世界の一部分。Marrのレベル(計算・アルゴリズム・実装)で同じエージェントを異なる粒度で分析できる。
第3週 — エージェントはどう推論・決定するのか?
• 規範的には:ベイズ + 期待効用
• 記述的には:ヒューリスティック、バイアス、プロスペクト理論
• ギャップこそ設計の住処。
Where we’re going — Week 4 & beyond次週:第4週と以降
Week 4: multi-agent dynamics.
What happens when agents interact?
• Multiple agents, shared resources (the fishing village + its neighbors)
• Tragedy of the commons
• Coordination, signaling, trust
“How do I decide?” becomes “what happens when we ALL decide?”
MP4 — fishing policy as choice architecture. You’ll design the rules: defaults, framing, norms. Today’s nudging segment was the toolkit. MP4 is the application.
第4週:マルチエージェント動学。
エージェントが相互作用すると何が起こるか?
• 複数エージェント、共有資源(漁村と隣接する村)
• コモンズの悲劇
• 協調、シグナリング、信頼
「私はどう決めるか」が「皆で決めるとどうなるか」に変わる。
MP4 — 選択アーキテクチャとしての漁業政策。ルールを設計する:デフォルト、フレーミング、規範。今日のナッジングがツールキット。MP4が応用編。