Week 6 — Social Cognition & Behavioral Game Theory第6週 — 社会的認知と行動ゲーム理論
June 4 (Thu), 20262026年6月4日(木)
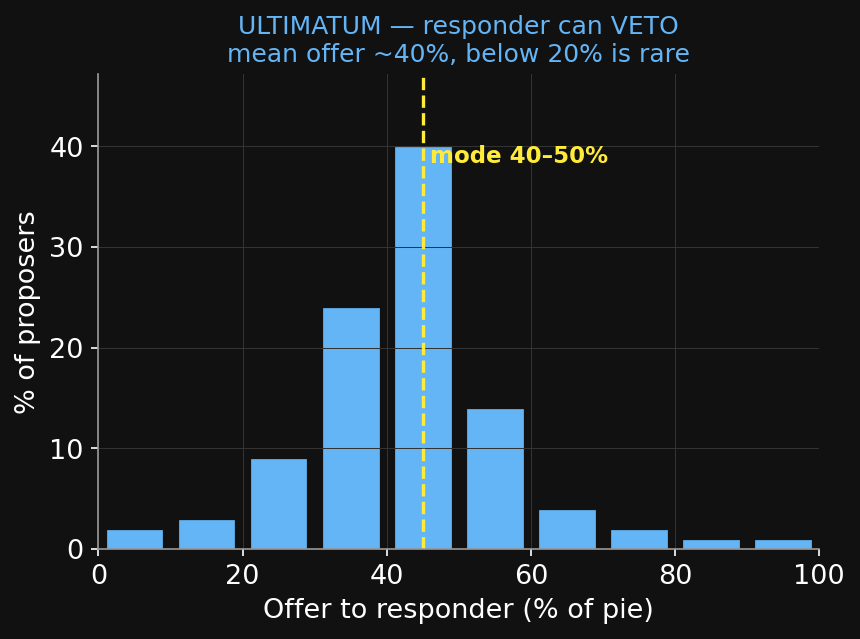
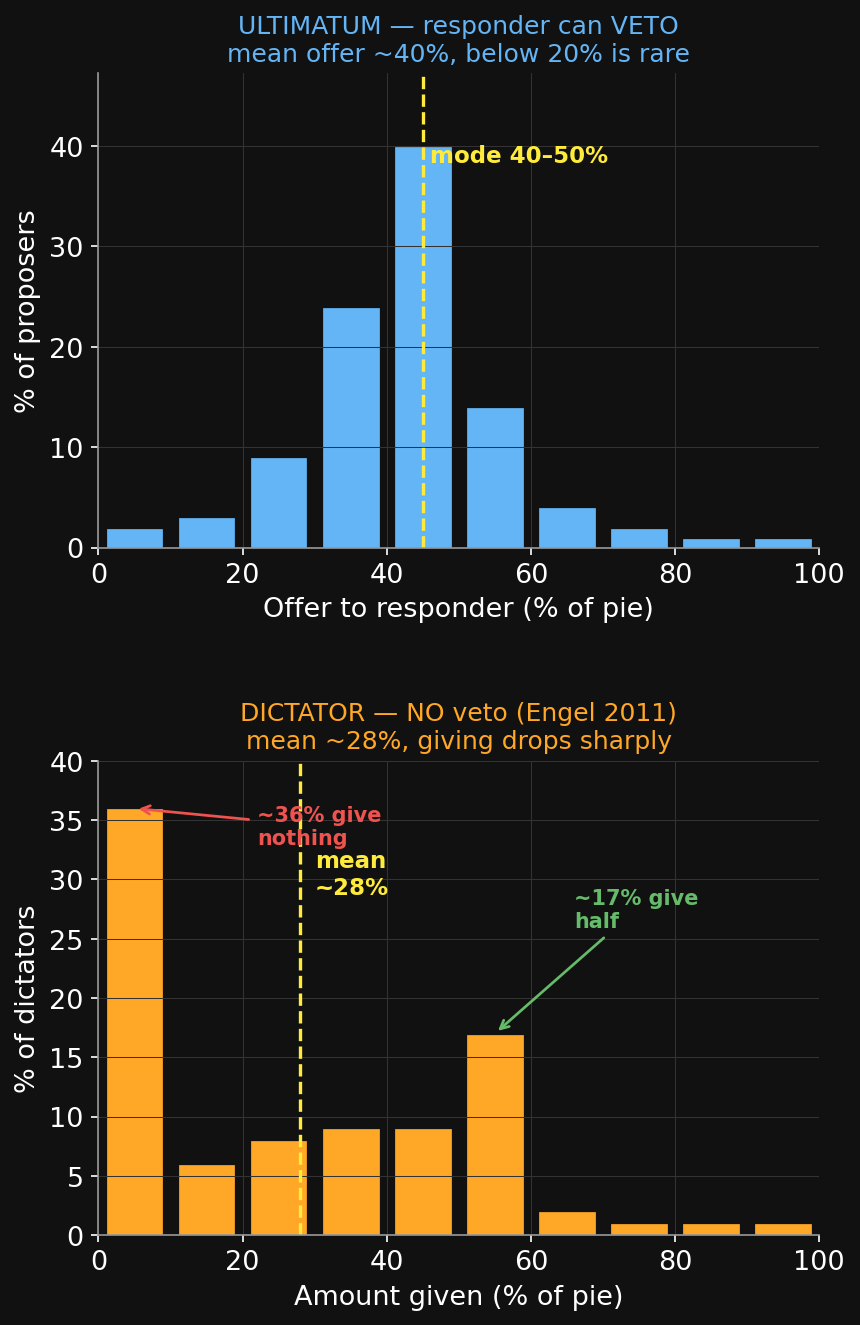
What people actually offer — ultimatum人が実際に提案する額 — 最後通牒
In Western lab samples (Güth et al. 1982; Camerer 2003 synthesis of 30+ studies):
- Modal & median offer: 40–50% of the pie. Mean ≈ 40–45%.
- Offers below ~20% are rejected about half the time (and more often as they shrink).
- Almost no one offers more than 50%.
The rational prediction — offer the smallest positive amount, accept anything — is wrong. Responders pay to punish unfairness; proposers anticipate it.
How does this compare to our room?
欧米の実験室サンプルでは(Güth et al. 1982;Camerer 2003 が30以上の研究を総括):
- 最頻・中央の提案:パイの40〜50%。平均 ≈ 40〜45%。
- 約20%未満の提案は約半分の確率で拒否される(小さくなるほど拒否率は上がる)。
- 50%を超える提案はほとんどない。
合理的予測 — 最小の正の額を提案し、何でも受け入れる — は間違い。受け手はコストを払って不公平を罰し、提案者はそれを見越す。
我々の部屋とどう違う?
What people actually give — dictator人が実際に与える額 — 独裁者
Engel (2011) meta-study — 600+ treatments, 100+ papers:
- Mean given ≈ 28% (vs. ~40% in the ultimatum game).
- ~36% give nothing. ~17% give exactly half. ~64% give something.
Removing the veto roughly halves giving. So part of “ultimatum fairness” was fear of rejection — but a real chunk of pure other-regard remains (most people still give something).
Engel (2011) メタ研究 — 600以上の処理、100以上の論文:
- 平均で約28%を分配(最後通牒の約40%に対して)。
- 約36%は何も与えない。約17%はちょうど半分。 約64%は何かを与える。
拒否権を外すと、分配はおよそ半分に。つまり「最後通牒の公平さ」の一部は拒否への恐れだった — しかし純粋な他者配慮もかなり残る(大半はそれでも何かを与える)。
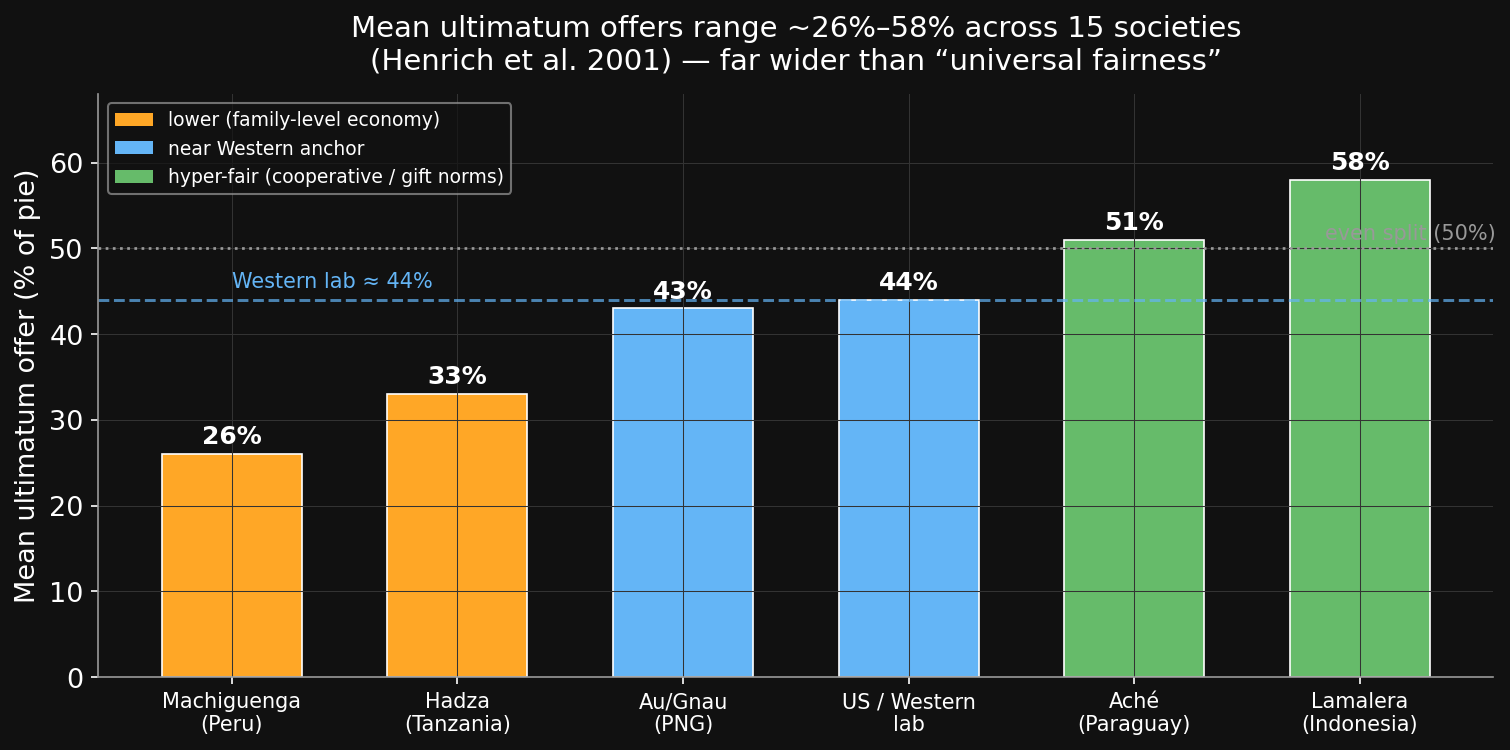
Offers range from 26% to 58%提案額は26%から58%まで
- Machiguenga (Peru, family-level farming): mean ~26% — and almost no rejections, even of low offers.
- Lamalera (Indonesia, cooperative whale hunters): mean ~58% — hyper-fair.
- Au & Gnau (Papua New Guinea): often reject hyper-fair offers — accepting a big gift creates a debt.
The pattern: the more a society depends on cooperation in production and market exchange, the fairer the offers — these two factors explain ~68% of the variance across societies (Henrich et al. 2001).
- マチゲンガ(ペルー、家族単位の農耕):平均約26% — そして低い提案でもほとんど拒否しない。
- ラマレラ(インドネシア、協同の捕鯨民):平均約58% — 超公平。
- アウ族とグナウ族(パプアニューギニア):しばしば「超公平」な提案を拒否する — 大きな贈り物を受け取ると負債が生じるため。
パターン: 社会が生産における協力と市場交換に依存するほど、提案は公平になる — この二つの要因が社会間のばらつきの約68%を説明する(Henrich et al. 2001)。
The reasoning ladder推論のはしご
- Level 0: guess randomly → average ≈ 50.
- Level 1: “if others are random, I guess ⅔ × 50 ≈ 33.”
- Level 2: “if others think that, I guess ⅔ × 33 ≈ 22.”
- Iterate forever → the only Nash equilibrium is everyone guesses 0.
But did anyone here guess 0? Almost nobody ever does.
- レベル0: ランダムに予想 → 平均 ≈ 50。
- レベル1: 「他人がランダムなら、⅔ × 50 ≈ 33と予想」。
- レベル2: 「他人がそう考えるなら、⅔ × 33 ≈ 22と予想」。
- 永遠に反復 → 唯一のナッシュ均衡は全員が0と予想。
でも、ここで0と予想した人は? ほとんど誰もいない。
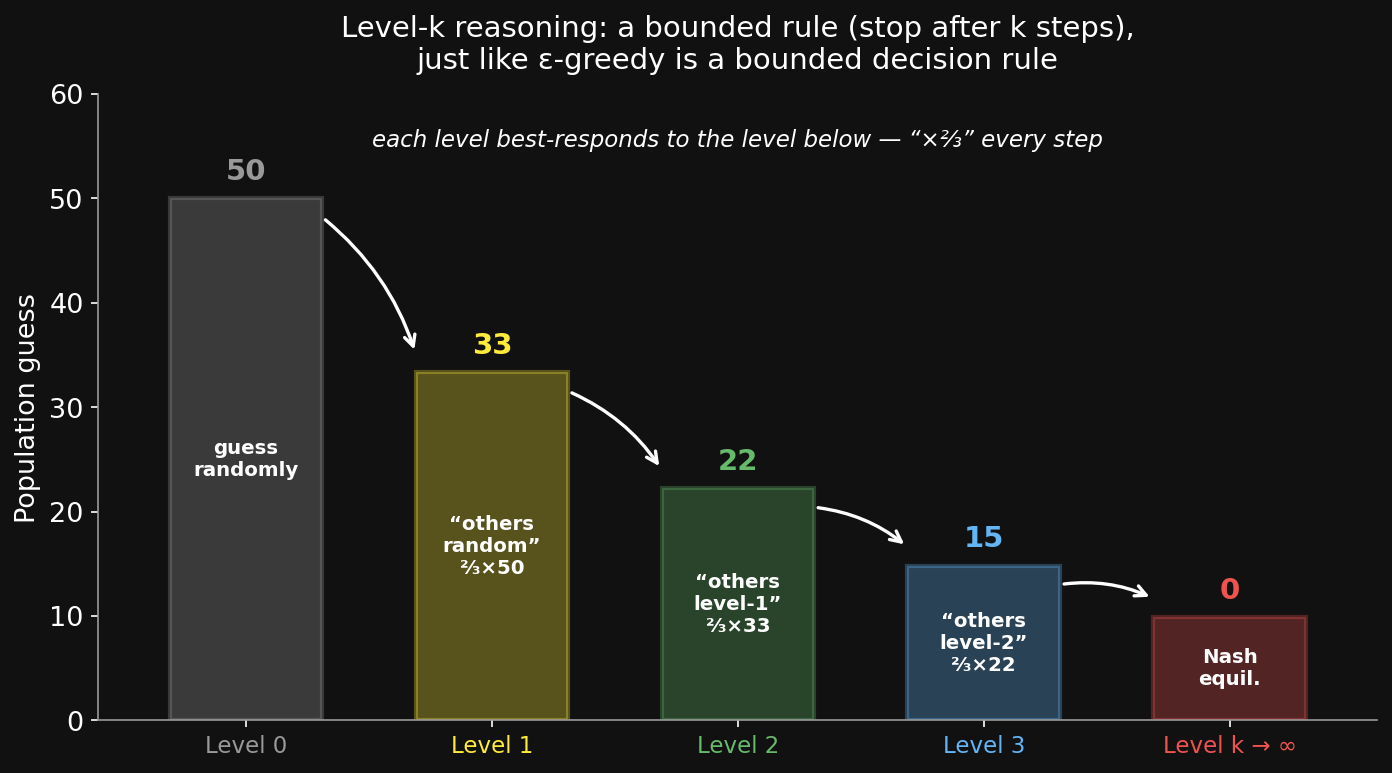
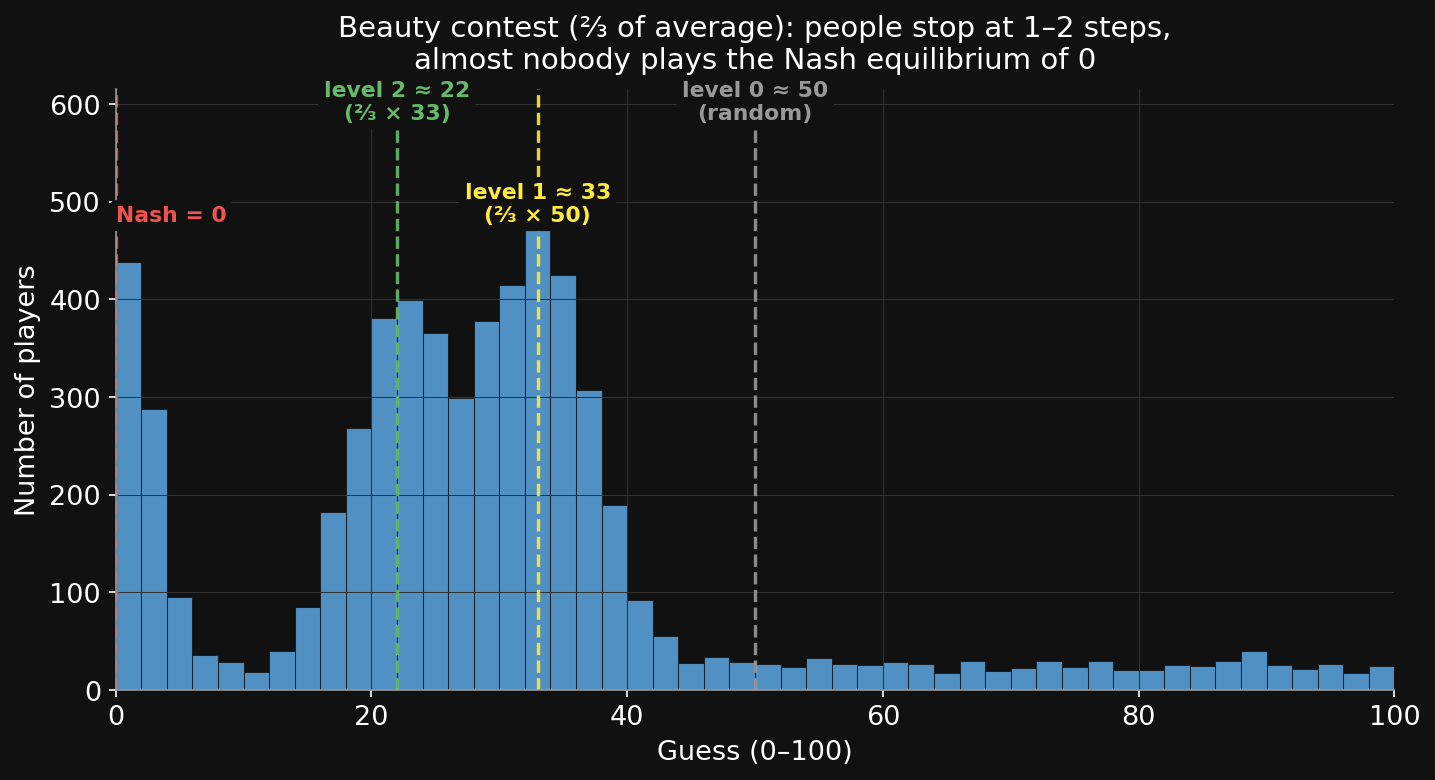
What people actually do人が実際にすること
Across thousands of players (Nagel 1995; Bosch-Domènech et al. 2002 newspaper experiments), guesses cluster at 33 and 22 — people do 1–2 steps, not infinite.
The cognitive-hierarchy model (Camerer, Ho & Chong 2004) puts the mean number of thinking steps at ≈ 1.5.
Depth of reasoning about other minds is not all-or-nothing — it’s a number, and you can measure it.
何千人ものプレイヤーで(Nagel 1995;Bosch-Domènech et al. 2002 の新聞実験)、予想は33と22に集中 — 人は1〜2ステップで、無限ではない。
認知階層モデル(Camerer, Ho & Chong 2004)は、平均の思考ステップ数を ≈ 1.5とする。
他者の心についての推論の深さは、全か無かではない — それは数値であり、測定できる。
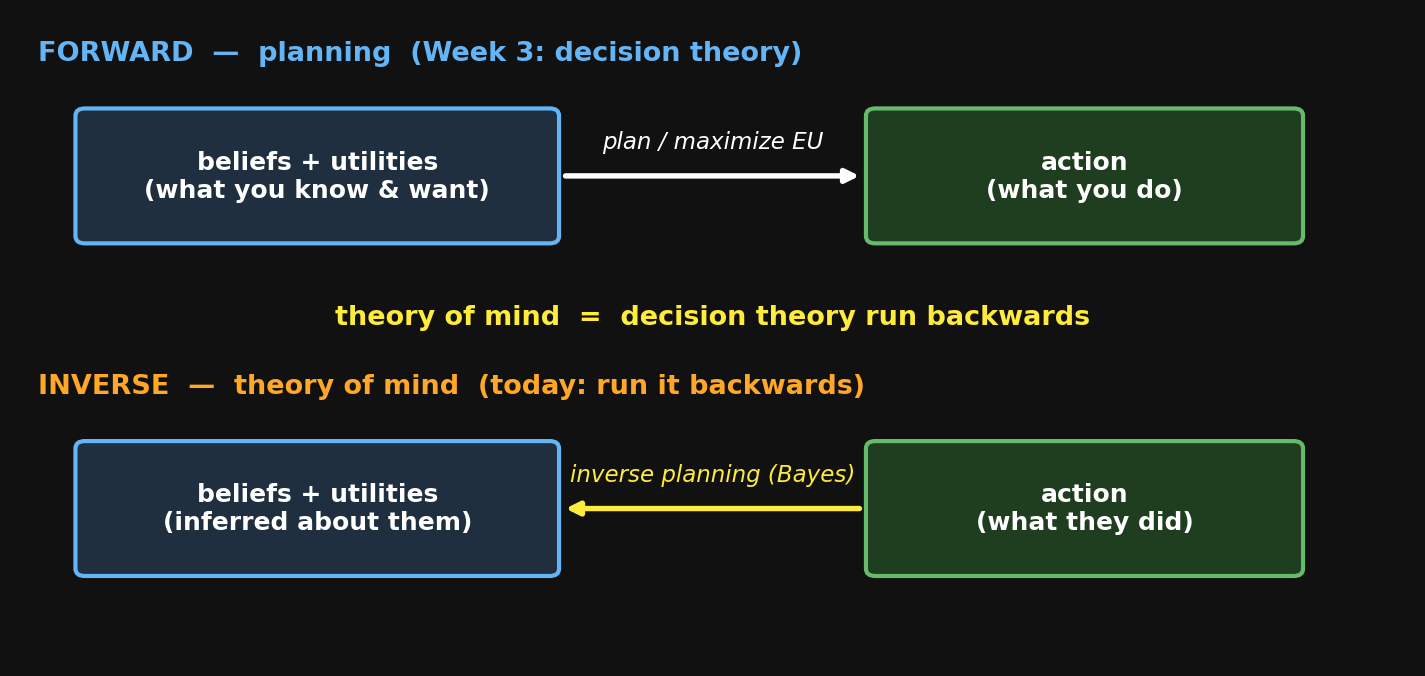
The computational turn計算論的転回
How does mature theory of mind actually work? Baker, Saxe & Tenenbaum (2009): “Action understanding as inverse planning.”
- Week 3: beliefs + utilities → action (planning)
- ToM: action → beliefs + utilities (inverse planning)
Theory of mind is your own decision theory, run backwards on someone else.
成熟した心の理論は実際どう働くのか? Baker, Saxe & Tenenbaum (2009):「逆プランニングとしての行動理解」。
- 第3週:信念 + 効用 → 行動 (プランニング)
- 心の理論:行動 → 信念 + 効用 (逆プランニング)
心の理論とは、自分の意思決定理論を他者に対して逆向きに動かすことです。
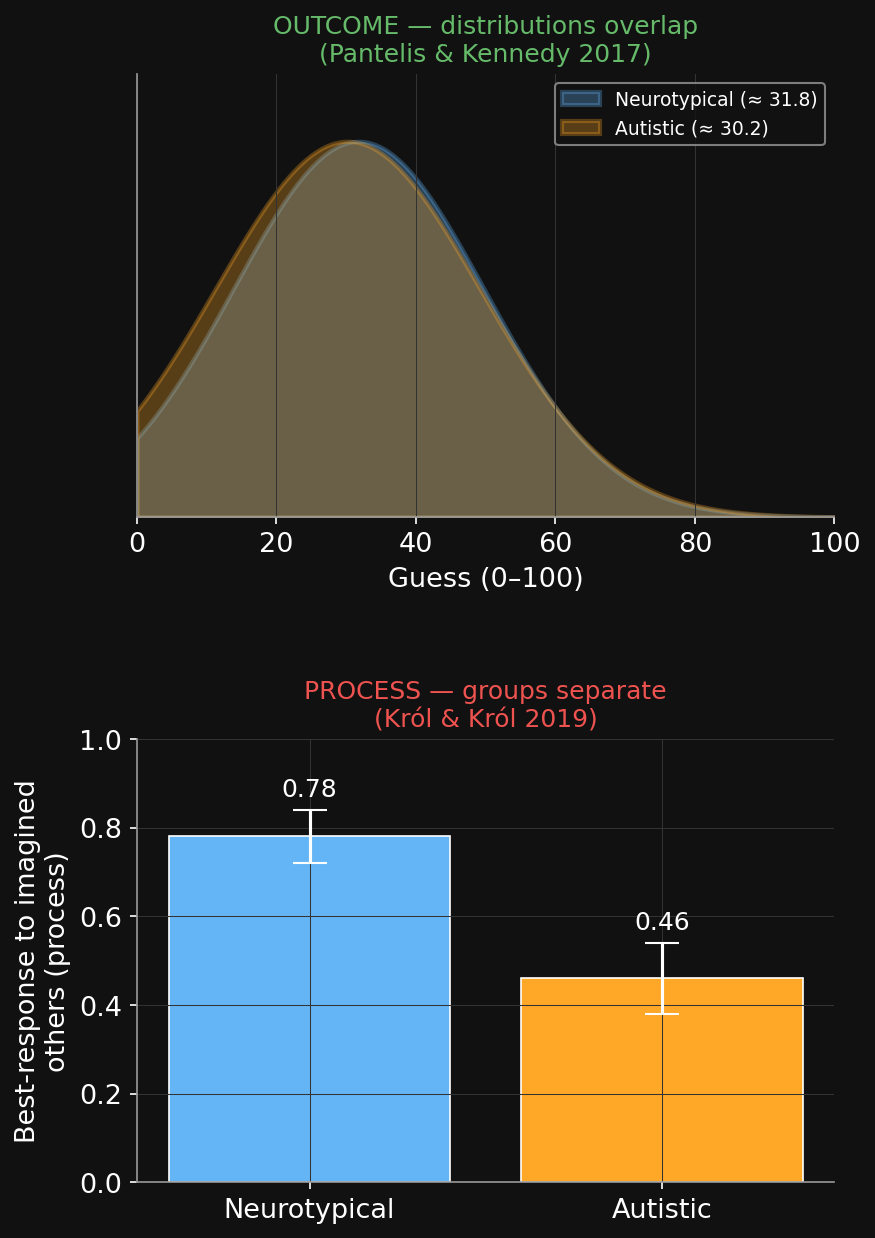
Result 1 — the surprise結果1 — 意外な結果
Pantelis & Kennedy (2017), Cognition — “Autism does not limit strategic thinking in the beauty contest game.”
- ASD vs. neurotypical: statistically indistinguishable in strategic depth.
- ASD mean ≈ 30.2, controls ≈ 31.8; same share of “higher-order” players.
- Bayes Factor: moderate evidence for the null.
Look how nearly identical the two distributions are →
Pantelis & Kennedy (2017), Cognition — 「自閉症は美人投票ゲームでの戦略的思考を制限しない」。
- ASD 対 定型発達:戦略的深さで統計的に区別できない。
- ASDの平均 ≈ 30.2、対照群 ≈ 31.8;「高次」プレイヤーの割合も同じ。
- ベイズ因子:帰無仮説を中程度に支持。
二つの分布がほぼ同一なことに注目 →
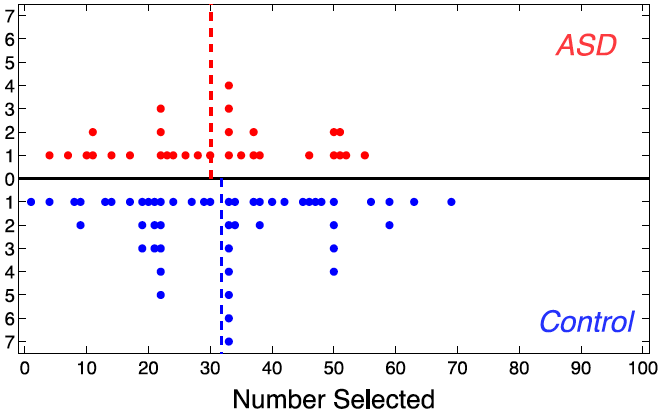
Guess distributions, ASD (top) vs. control (bottom) — the dashed mean lines almost coincide. (Pantelis & Kennedy 2017, Exp 2)
Result 2 — the reversal結果2 — 逆転
Król & Król (2019), Thinking & Reasoning — “Autism limits strategic thinking after all.”
- They replicated the outcome null — but added a payoff calculator to trace the process.
- Neurotypicals played best-response to the hypothetical others they entered.
- Autistic participants were less strategic in process — answers larger relative to what they attributed to others — even though the final numbers matched.
Outcome (top): same. Process (bottom): different. →
Król & Król (2019), Thinking & Reasoning — 「やはり自閉症は戦略的思考を制限する」。
- 彼らは結果の帰無を再現 — しかし過程を追跡するペイオフ計算機を加えた。
- 定型発達者は、入力した仮想の他者に対して最適応答を行った。
- 自閉症の参加者は過程において戦略性が低かった — 自分が他者に帰属させた値に比べて答えが大きかった — 最終的な数値は一致していたにもかかわらず。
結果(上):同じ。過程(下):異なる。 →
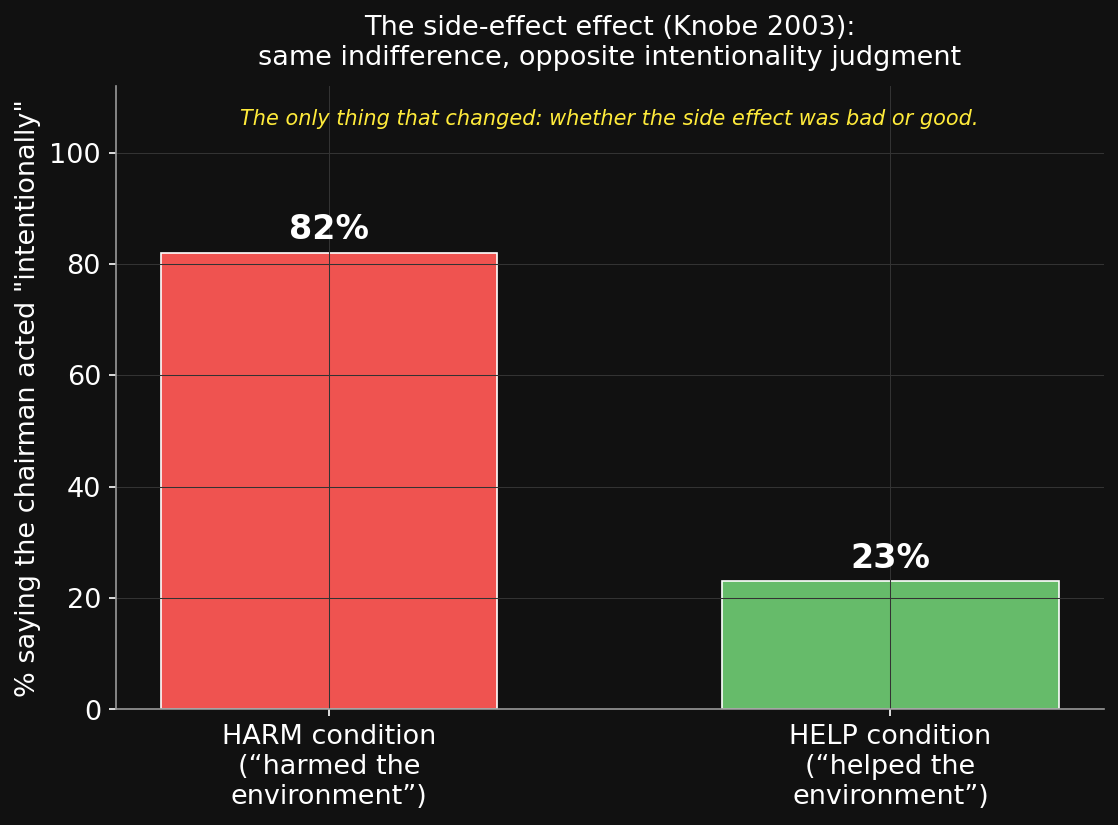
The side-effect effect副作用効果
Knobe (2003) — across studies:
- 82% say he harmed the environment intentionally (≈ your show of hands).
- Flip one word to help — same indifferent chairman — and only 23% say he helped intentionally.
He had the same mental state both times: he didn’t care. A reasons-first (blame-late) account would call both unintentional.
Yet “intentional” tracks bad vs. good, not his actual intent — the badness comes first and pulls the judgment with it.
Knobe (2003) — 複数の研究で:
- 82% が、彼は環境を害したのは意図的だと言う (≈ 皆さんの挙手)。
- 一語を助けるに変えると — 同じ無関心な会長 — 23% しか助けたのは意図的だと言わない。
彼の心的状態は両方で同じ — どうでもよかった。理由先行(遅い非難)ならどちらも非意図的と呼ぶはず。
それでも「意図的」は彼の実際の意図ではなく悪いか善いかを追う — 悪さが先に来て判断を引きずる。
Blame early: re-reading the Knobe effect早い非難:クノービ効果の再解釈
Look back at the chairman. The story, his indifference, the structure — all identical. Only the outcome’s valence flipped: harm vs. help.
- Harm → 82% call it intentional. Help → 23%.
If intentionality were read off behavior first and fed into blame, valence couldn’t move it. Instead it looks like we judge the actor bad first (he didn’t care, and harm resulted) — and that verdict pulls “intentional” along with it.
Affect about the agent shaping a judgment that’s supposed to be an input to blame: that’s blame early.
会長の話に戻りましょう。話も、彼の無関心も、構造も — すべて同一。変わったのは結果の価だけ:害 対 益。
- 害 → 82%が意図的と判断。 益 → 23%。
もし意図性がまず行動から読み取られ、それが非難に入力されるなら、価がそれを動かせるはずがない。むしろ、我々はまず行為者を「悪い」と判断し(彼は気にせず、害が生じた)、その判断が「意図的」を引きずってくるように見える。
非難への入力であるはずの判断を、行為者への情動が形づくる — それが早い非難。
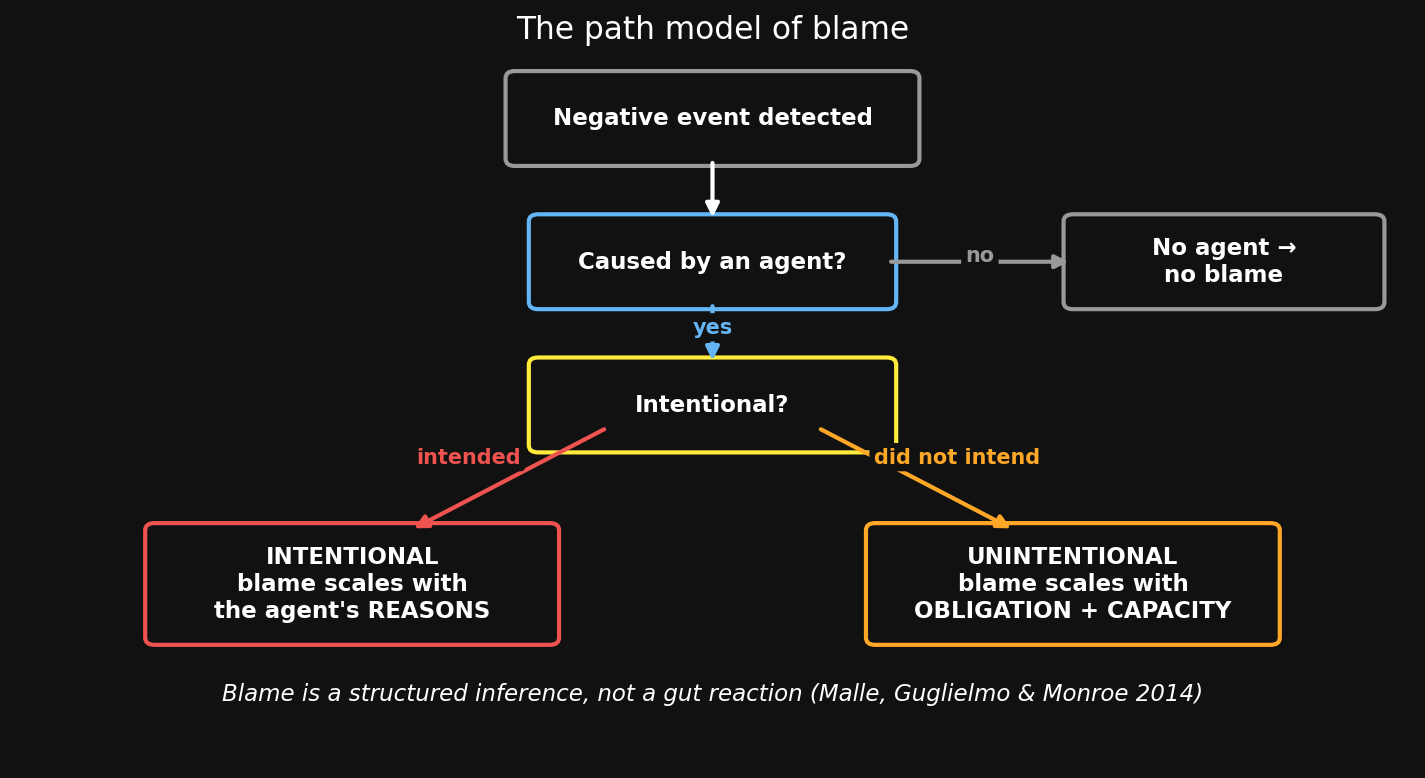
Evidence for blame late (Malle, Guglielmo & Monroe 2014): much blame is structured reasoning, not reflex —
- Detect a negative event.
- Was there a causal agent? (No → no blame.)
- Was it intentional?
- Intentional → blame scales with the agent’s reasons (selfish → more; good goal → less).
- Unintentional → blame scales with obligation + capacity (should they have prevented it, and could they?).
Intent raises blame for the same outcome (manslaughter vs. homicide); lack of knowledge lowers it. The inverse-planning machinery again — cause → intent → reasons.
遅い非難の証拠(Malle, Guglielmo & Monroe 2014):非難の多くは反射ではなく構造化された推論 —
- 否定的な出来事を検出。
- 原因となるエージェントがいたか?(いない → 非難なし。)
- それは意図的だったか?
- 意図的 → 非難はエージェントの理由に応じて増減(利己的 → 増、善い目的 → 減)。
- 非意図的 → 非難は義務 + 能力に応じて増減(防ぐべきだったか、そして防げたか)。
同じ結果でも意図が非難を高める(過失致死 対 殺人);知識の欠如は下げる。再び逆プランニングの仕組み — 原因 → 意図 → 理由。
Both — and the verdict is social両方 — そして判断は社会的
So which is it? Both — fast affect and structured reasoning run, and they interact.
And the verdict isn’t even purely individual — the group bends it.
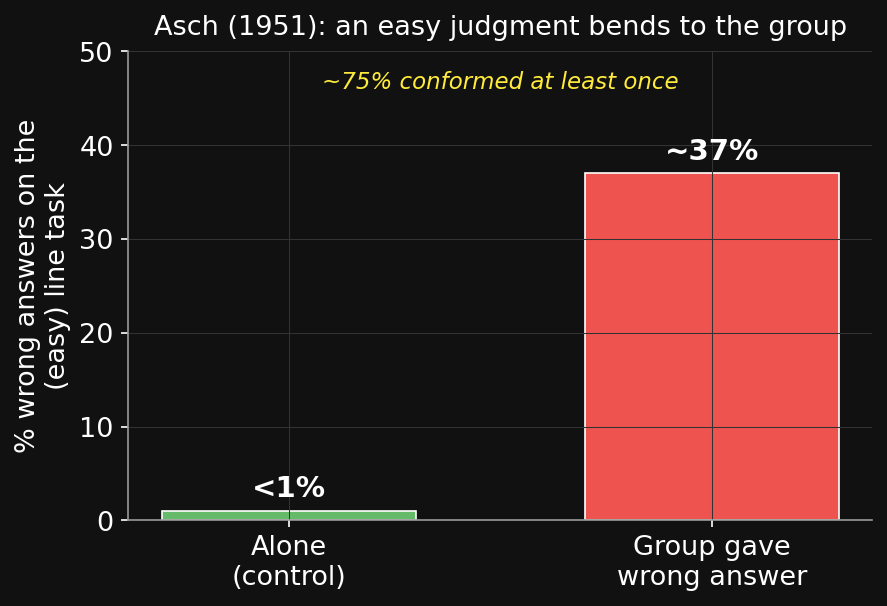
Asch (1951): pick which line matches — easy, unambiguous. But confederates all give the same wrong answer.
- ~37% conformed on critical trials; ~75% at least once (alone: <1% errors).
- Mostly normative (fit in), not informational — people saw the right answer and went along.
If even line-length perception bends to the group, so does moral judgment.
ではどちら? 両方 — 速い情動と構造化された推論が働き、相互作用する。
そして判断は純粋に個人的でさえない — 集団がそれを曲げる。
Asch (1951): どの線が一致するか選ぶ — 簡単で曖昧さがない。しかしサクラ全員が同じ誤答をする。
- 約37%が重要試行で同調;約75%が少なくとも一度(単独なら誤答1%未満)。
- 大半は規範的(馴染むため)で情報的ではない — 正答が見えていながら合わせた。
線の長さの知覚でさえ集団に曲げられるなら、道徳的判断もそうなる。